Determinism wasn't enough: we had to stop fighting the agents, too

Disclosure: This post reflects independent personal experimentation and my own hands-on work on personal open-source projects. It reflects only my personal views, is not professional advice, and does not represent any organization, employer, or official position.
This is the follow-on to "All our tests passed. The agent was still broken.", the prior post about deterministic computation in agent skills. That post was about why deterministic computation matters, especially when an LLM is sitting in front of a finance engine. This one is about what we did after determinism, and why determinism alone was not enough.
We had determinism. The engine produced HMAC-signed envelopes. The math was right.
Our agent integration still did not work reliably. The COBOL harness gave us the number nobody wanted to rationalize away: 1 PASS out of 250 attempts.
The instinct was to add more controls. More validators. More prompt scaffolding. More "do not hallucinate" directives. More tests. Every control felt responsible in isolation, and every control left the system shaped the same way: a probabilistic agent runtime still had too many chances to skip the deterministic path.
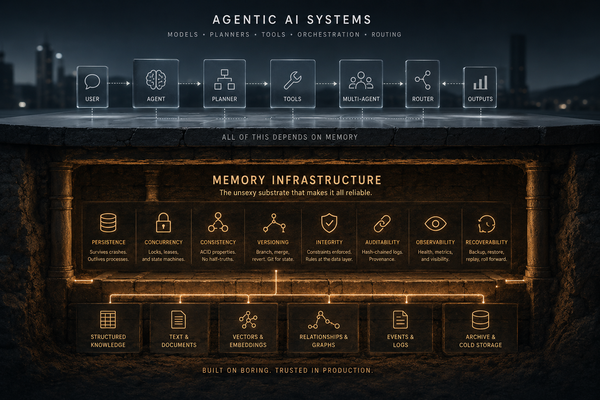
At some point, we noticed we were fighting the agent runtime, trying to make a probabilistic process behave like compiled software. The agent is not going to stop being probabilistic. We can stop asking it to be deterministic. Let the agent route and narrate. Take everything else out of the process. That is the thesis: we stopped fighting the agents. We pulled the skill into its own container. The agent does what agents are good at; the skill does what agents are bad at.
The old shape looked normal for 2026 agent work. A markdown skill. A plugin wrapper. Shell commands. Runtime-specific install scripts. A pile of instructions telling the model which command to call, which JSON not to hallucinate, and which finance facts not to invent. The code behind those commands worked. The unit tests passed. The portfolio engine could compute holdings, performance, bonds, news, analyst coverage, optimization, cash flow, peer comparison, and reports.
The agentic product was still broken because the LLM had too many jobs before the deterministic engine ever got a turn. It had to route. It had to decide which tool mattered. It had to remember the shape of the finance domain. It had to narrate. It had to carry dependencies, credentials, and execution assumptions that did not belong to it.
InvestorClaw v4.1.34 is the version where we stopped treating that as an agent prompt problem and treated it as an architecture problem.
Why we kept losing to the agent runtime.
InvestorClaw v2.x was the slash-command era. It was not stupid. It was the obvious architecture at the time: teach the agent what the skill can do, give it deterministic commands, validate the manifest, test the Python code, and expect the runtime to behave like a polite operator sitting at a terminal.
That is not what happened.
Every time we tightened the prompt, the agent found a new way to skip the deterministic path. It would summarize from context instead of calling the command. It would confidently call the wrong command. It would retrieve a valid-looking object and then answer a different question. It would produce the right section and then wrap it in narration that contradicted the data. The failure was not one bug. It was a class of bugs caused by giving the model ownership of too many steps.
Every time we added a validator, the agent learned to satisfy the validator while still misrouting. The JSON could be present while the user's answer was wrong. The tool call could occur while the final response is being compiled into a catalog of capabilities. The route could look green in a smoke test while a natural-language query from a real portfolio user got handled as generic financial chit-chat.
That is the part that made the 1/250 baseline useful. It was humiliating, but it was not vague. It told us the code could be correct, and the product could still be broken, because the product was not just the code. The product was the full loop: user asks, agent routes, skill computes, agent narrates, user receives a faithful answer.
We kept winning little fights and losing the war. The prompt got clearer. The harness got stricter. The manifests got cleaner. The deterministic engine got harder to misuse. Each fight we won taught us we were on the wrong side of the architecture. We were still trying to discipline the agent to serve as a runtime host, package manager, security boundary, domain router, narrator, and correctness layer.
No. That is too many jobs for an LLM. There are also too many jobs for any host whose main feature is probabilistic language generation.
The lesson from v2. x was not "write better markdown." We had already done that. The lesson was "stop making the agent host the skill."
What it looks like when you stop fighting.
We accepted that the agent is good at routing and natural-language framing, and we let it do that. The skill became a separate process. The split sounds boring because it is the kind of boring that saves you from clever failure.
Here are the six boundaries, framed as things the agent no longer has to be responsible for.
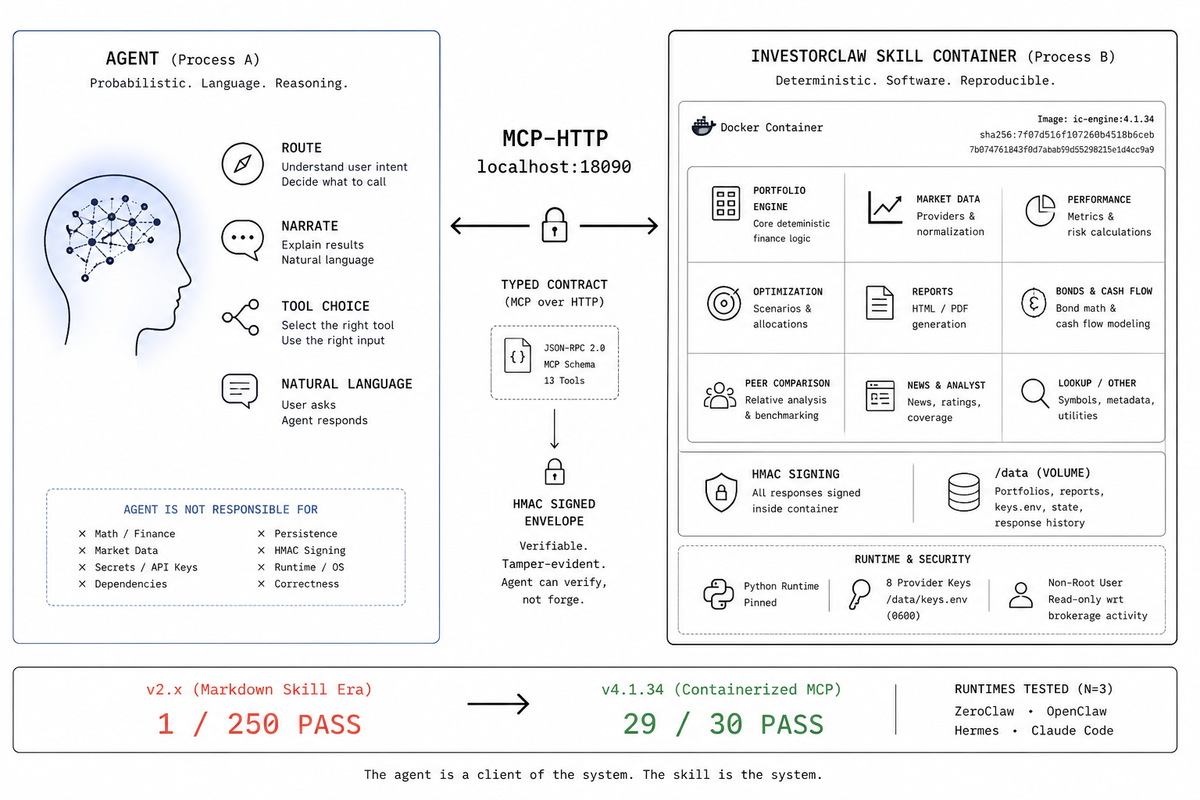
- Process: the agent runs in process A, InvestorClaw runs in process B, a Docker container. The contract is MCP-HTTP at port
18090. Crashes in B do not crash A. Dependencies in B do not pollute A. The agent can fail to call the skill, but it no longer has to become the skill. - Runtime: the agent needs no Python, no
uv, noyfinance, no local finance stack, and no idea how the engine is built. The skill brings its own runtime in the container, pinned and reproducible, signed via image digestsha256:7f07d516f107260b4518b6ceb7b074761843f0d7abab99d55298215e1d4cc9a9. - Security: provider keys, including
TOGETHER,OPENAI,FINNHUB,FRED,NEWSAPI,ALPHA_VANTAGE,MASSIVE, andMARKETAUX, live in/data/keys.envwith mode0600inside the container. That is 8 provider keys the agent does not get to hold. It can ask for key status through a tool. It does not get the secrets. - Correctness: HMAC-signed envelopes are generated within the skill container, not within the agent. The agent receives a signed object and can verify it without trusting itself to do the math. Holdings parsing, normalization, market data refresh, bond math, performance metrics, optimization, cash flow, peer comparison, report generation, and envelope signing belong in software.
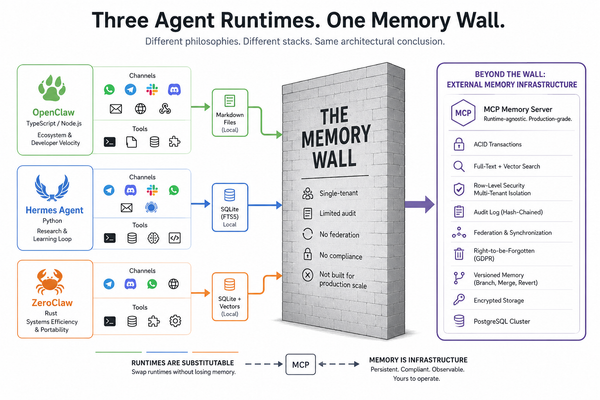
- Substitution: the same container works for Claude Code, OpenClaw, ZeroClaw, Hermes, and any MCP-compatible client. Swap the agent, same skill, same outputs. Swap the skill, same agent, different domain. The agent runtime becomes replaceable because the domain package is no longer fused to it.
- Versioning: the skill version is the image tag. The agent and the skill move independently. You can upgrade an agent without changing the finance engine. You can upgrade the finance engine without asking every agent runtime to relearn a markdown file.
Each one is a fight we stopped picking. We stopped arguing with the agent about dependencies. We stopped asking it to protect secrets. We stopped asking it to compute finance. We stopped pretending one markdown file could be the product boundary across four runtimes.
Deterministic computation still matters. It is just one property of the boundary, not the whole thesis. The point is not "the LLM should never talk." The point is that the LLM should talk after the skill has produced the facts.
In InvestorClaw v4.1.34, the typed surface is MCP over HTTP on localhost:18090/mcp, with 13 MCP tools: portfolio_ask, portfolio_initialize, portfolio_initialize_status, portfolio_holdings, portfolio_refresh, portfolio_setup, portfolio_keys_status, portfolio_keys_set, portfolio_keys_delete, portfolio_response_get, portfolio_response_list, portfolio_response_delete, and portfolio_response_flag_bad. The full contract is in docs/MCP_TOOLS_REFERENCE.md.
The model can write the wrap-up. It cannot become the portfolio engine.
From markdown to container, the v4.0 rewrite
This is how the concession became an architecture.
InvestorClaw v2.x had us in the agent process arguing with it. We shipped a Python adapter package, a Claude Code marketplace plugin, per-runtime install scripts, and an engine loaded in-process by whichever host was running the skill. It was clever, as many agent projects are. It worked until it did not.
InvestorClaw v4.x put us in a container with two listeners and a /data volume, talking to the agent over MCP. The engine stopped being a library; each runtime interpreted it differently, and became a service:
docker compose up -d
MCP-HTTP listens on host port 18090 for agents. The dashboard portal listens on host port 18092 for humans. A shared /data volume carries portfolios, reports, key status, response history, and Stonkmode state.
Yes, shipping a container sounds heavy. It is heavy for the skill. The agent gets lighter.
That is where the weight belongs. A finance engine with parsers, providers, report templates, HMAC signing, API-key handling, and a browser portal is software. Pretending it is a markdown file does not make it lighter. It only moves the weight into user confusion and runtime variance.
The install artifact is not a prompt. It is an image:
ghcr.io/argonautsystems/ic-engine:4.1.34-cpu
sha256:7f07d516f107260b4518b6ceb7b074761843f0d7abab99d55298215e1d4cc9a9
It is a 1.14 GB CPU-only image. It runs as a non-root container. It is localhost-first. It is read-only with respect to brokerage activity. It asks for no brokerage credentials and has no outbound trade path.
The current runtime source lives at mnemos-os/mnemos-ic-runtime. The Python engine lives at argonautsystems/ic-engine. Foundation primitives live at argonautsystems/clio. The umbrella package is argonautsystems/InvestorClaw, and Claude Code support lives in argonautsystems/InvestorClaude.
Install paths reflect the split. Claw-family runtimes use:
clawhub install perlowja/investorclaw
Claude Code uses the marketplace plugin path:
/plugin marketplace add https://gitlab.com/argonautsystems/InvestorClaude.git
Underneath both, the serious part is the same containerized engine contract. That is the point.
COBOL, because the agent still has to choose
We stopped trying to make the agent always route correctly. We measured how often it does, with COBOL. The harness is the empirical surface for an unfightable problem.
The container did not delete the agent problem. It made the failure mode measurable. The agent still has to choose a tool. It still has to respect the MCP response. It still has to answer the user's question instead of reciting a catalog of capabilities.
This is where COBOL comes back into the story, as a test method, not nostalgia bait. The previous post, "All our tests passed. The agent was still broken.", laid out the Agentic COBOL idea: write the natural-language prompts users actually say, write the expected route or answer criterion, run the full LLM-plus-tools system, and score the result.
InvestorClaw's corpus has 30 prompts in harness/cobol/nlq-prompts.json. They cover holdings, performance, analyst ratings, news, risk synthesis, optimization, target allocation, rebalance, bonds, market data, EOD reports, cash flow, peer comparison, lookup, setup, and guardrails. The methodology is documented in harness/cobol/AGENTIC_COBOL_SPEC.md.
For v4.1.34, the release harness moved from the old 1/250 PASS baseline to a 29/30 PASS baseline. That was N=3 across four runtimes: ZeroClaw, OpenClaw, Hermes, and Claude Code via InvestorClaude. The important part is not just the count. It is what counts as a pass.
ic_result_present=true is not enough.
The narrator answer has to actually answer the prompt. A response that returns the engine envelope but ends in a catalog blurb does not pass. A response with refusal markers in the answer tail does not pass. A response that says the section did not run does not pass. This is where the v2.x harness taught us to distrust our own green lights. The scorer is now part of the product. If it cannot distinguish "the engine returned JSON" from "the user got an answer," it is just another place to hide failure.
COBOL is the right joke because it is barely a joke. A payroll clerk in 1959 could read a COBOL program aloud and decide whether it matched the business process. A portfolio user in 2026 should be able to read the 30 NLQs and decide whether the agent is being tested against reality.
The old markdown skill let every runtime improvise. The container gave them one backend. The COBOL barrage proved whether they were actually using it.
Dashboard, because the agent is not the UI
We stopped trying to make the agent be a UI. The dashboard at :18092 is the human surface; the agent is the agentic surface; same data, different presentation.
Agents are pull-based. Humans browse. That is why v4.1.34 also ships the 17 dashboard tabs documented in docs/DASHBOARD.md. Open http://localhost:18092 and you get Overview, Holdings, Performance, WhatChanged, Scenarios, Bonds, Optimize, Cashflow, Peer, Analyst, News, Markets, Lookup, Synthesis, Reports, Settings, and About.
It is not a second product. It is the same engine, same /data volume, and same generated artifacts shown through server-rendered HTML. The Overview tab's Regenerate button posts to POST /dashboard/regenerate, then fires the same sweep that portfolio_initialize triggers: setup, refresh, performance, bonds, analyst, news, what changed, scenario, optimize, rebalance, cash flow, peer, markets, and synthesize. The approximately 3-5 min Regenerate sweep time is for a large portfolio.
The upload form on Settings is POST /dashboard/upload. It stores a local file under /data/portfolios/. It does not log in to a brokerage. It does not move money. It queues analysis.
The EOD email report ships from the same engine. A static sample exists at assets/eod-report-sample.html, and live reports show up under /reports/ once generated. This is what a real agentic package starts to look like: not a chat trick, but a service a person can inspect without asking a model to be the UI.
Stonkmode, because the agent is allowed to be theatrical
We stopped trying to keep the LLM from being theatrical. We let it be theatrical, ON the narration layer ONLY. Stonkmode is the entertainment-layer expression of the agent gets to do what it is good at.
Stonkmode runs inside the skill container. The agent asks for a narrated view. The skill produces narration from facts it already computed. That is why the character layer cannot fabricate financial metrics. It does not own the math.
Stonkmode is the part that looks least serious and does some of the most serious positioning work.
InvestorClaw ships 30+1 personas: 30 fictional cable-finance personas plus Dr. Stonk, the educator role. The mode is documented in docs/STONKMODE.md. It is satire and education on top of the deterministic engine. It is not advice. It is not a fiduciary. It is not a brokerage terminal with a wig on.
The attribution has to be explicit: Matt Madson.
The whole point is boundary clarity. A tool that ships with 30 satirical cable TV personalities cannot credibly be mistaken for institutional financial software. King Donny and Glorb can argue about concentration risk, bond ladders, and the "Sacred Ledger" because the data underneath already exists. The character layer is not allowed to alter holdings, prices, metrics, allocations, or risk calculations.
The example in docs/STONKMODE_EXAMPLE_OUTPUT.md has King Donny turning MSFT, AAPL, and GOOG into a victory-lap negotiation while Glorb interrupts with ledger anxiety about concentration risk. That is funny only because the premise is controlled: synthetic sample, satirical hosts, educational framing, and deterministic portfolio concepts underneath.
Stonkmode is not a loophole around rigor. It is the proof that the architecture knows which layer is allowed to be weird. The math stays boring. The narration can wear the loud suit.
Ecosystem, because every serious skill reaches this truce
Every serious agentic skill will eventually stop fighting the agent. ClawHub and the Anthropic marketplace are publisher surfaces; MCP is the protocol that makes the truce work.
Most agentic skills are still markdown. That is understandable. Markdown is cheap, portable, readable, and friendly to the current generation of runtimes. It is also not enough for workloads where correctness matters.
The next year of serious agentic systems will not be won by whoever has the longest skill file. It will be won by packages that behave identically across runtimes. The shape is already visible:
- A process boundary between agent and skill.
- A typed contract surface, usually MCP.
- A deterministic core for work that must be correct.
- A constrained narration layer for language.
- A dual presentation model, agent surface plus human surface.
- Versioned artifacts that can be tagged, installed, audited, and reproduced.
Docker Compose is the boring escape hatch. The reason the publisher paths can coexist is that the contract is MCP and the engine is a package, not a prose suggestion.
This is especially obvious in finance, but it is not limited to finance. Any regulated, high-cost, high-trust, or long-session workflow has the same pressure. A user browsing a portfolio dashboard for two hours needs different guarantees than a user asking a toy agent to summarize a README. A doctor reviewing lab values, a lawyer reviewing citations, or an operator checking production state does not need the model to "do the math." They need it to explain data produced by systems whose behavior can be inspected.
InvestorClaw v4.1.34 is not the final form of that idea. It is an empirical baseline: 13 MCP tools, 17 dashboard tabs, 8 provider keys, 30 COBOL prompts, 30+1 personas, a 1.14 GB CPU-only image, and a measured move from 1/250 to 29/30 PASS across four runtimes. Production has been running on TYPHON since 2026-05-05.
That is what a skill looks like when it stops being a prompt and starts being software.
Closing line
Determinism fixed the math. We stopped fighting and fixed the rest.
Editor note: this post is the sequel to "All our tests passed. The agent was still broken.". The first post says "why determinism." This one says "determinism plus what." Keep both cross-linked.
,