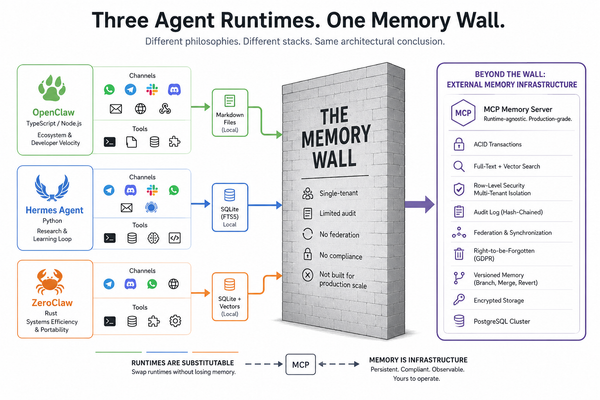
The Product That Didn't Exist


The original article in this series argued that no LLM product was deliberately designed for personal, persistent-agent, or continuous coding use. Anthropic shipped one piece of the answer on June 15. xAI shipped the other on May 19. This is what they are, why they exist, and how to architect around the gap they leave behind.
Disclosure: This post reflects independent personal experimentation and my own hands-on work on personal open-source projects. It reflects only my personal views, is not professional advice, and does not represent any organization, employer, or official position.
Three months ago, in "OpenClaw Backend Optimization: Groq vs. Claude for Persistent AI Agents", I argued that no LLM vendor had built a product designed for personal, persistent-agent, or continuous coding use. The economics did not fit. Subscription tiers were priced for chat-burst consumption rather than sustained agentic workloads. Per-token API rates that supported agentic workloads were structured for enterprise volume rather than for individual developers. The gap was real, and no vendor was moving to close it.

Sent to xAI investor relations and elon.musk@x.com on March 14, 2026. xAI announced SuperGrok and X Premium OAuth authentication for OpenClaw on May 19, 2026. Anthropic announced its Agent SDK credit pool on May 13, 2026, with an effective date of June 15.
I cannot prove that xAI received this email, read it, or gave it weight. They never responded. What I can prove is the sequence: a published analysis identifying the gap in February, a private memo to the company describing the specific integration with the partner on March 14, and a public announcement implementing that exact integration with that exact partner on May 19. Two months. Same product. Same business model. Readers are free to draw whatever conclusion the sequence supports.
This piece is about agentic coding, a related but different workload from the original article. The kind of work where you open a terminal, describe a task, and an agent reads files, writes edits, runs tools, and iterates until the work is done.
It looks like persistent-agent work because both involve autonomous tool use, but the token profile the model needs, and the optimal subscription structure, differ enough that the original article's analysis does not transfer directly. I have spent enough time running OpenCode, as my daily coding driver, to have real numbers on what these workloads actually cost across the provider landscape, and those numbers point to a specific direction.
The June 15 Anthropic change and the May 19 xAI announcement matter here as context, not as load-bearing events. The "Interactive Claude Code" in the terminal will remain in the subscription pool, which makes agentic coding economics structurally different from the agent SDK question. You are not choosing between subsidized chat and a metered agent. You are choosing between subsidized interactive coding and the OpenCode-plus-cheap-OSS-plus-Codex configuration that the rest of this piece works through.
If you're doing constant agentic coding work, the right answer isn't to pick one tool over another. It is splitting the workflow into architecture and iteration phases, routing each phase through the model and subscription that fits its shape, and right-sizing the Anthropic tier you pay for accordingly.
The Agentic Coding Workload
Coding agents (OpenCode, Aider, Claude Code, Codex CLI) operate on a particular shape. You open a terminal, describe a task, and the agent reads files, writes edits, runs shell commands, and iterates until the task is done or you kill it. This looks like a conversation. It is not.
Input is heavy, output is light. Every file the agent reads is input tokens. A 500-line Python file costs roughly 3,500 tokens each time the model needs to reason about it, and coding agents constantly re-read files. A 20-file refactor can generate 500K to 1M input tokens before a single line of output code is written.
Tool calls are cheap words with expensive consequences. A bash tool call is perhaps 40 tokens. The stdout piped back from grep -rn "function_name" . on a medium repository can be 8,000 tokens of pure input. Repeated tool invocations across a multi-file task compound this aggressively.
Edits are narrow. Output tokens (the actual code written) are modest relative to input. A patch fixing a 30-line function might generate 200 output tokens, compared to 50,000 input tokens, for the context loaded to produce it. The input-to-output ratio in agentic coding typically runs 6:1 to 10:1. In conversational chat, it inverts.
Context exhaustion is the failure mode. Unlike orchestration agents where the original analysis identified ~128K remaining headroom as the stability floor, coding agents hit context walls differently. The agent needs all the files it touched, not a summary. Truncation causes inconsistent edits. Invisible mid-session context drops cause bugs that appear to be hallucinations but are actually missing information.
The working unit for cost analysis is a session: roughly 300K input tokens and 50K output tokens at a 6:1 ratio, representing a medium-complexity task that touches several files and runs a handful of tools. Session totals scale linearly with codebase size and task complexity, but the ratio holds across most coding workloads.
Coding Models: Cost and Quality
Using the session as the working unit, the cost-quality landscape across the models worth considering for agentic coding work looks like this:
| Model | Tier | SWE-bench Verified | API cost / session | Notes |
|---|---|---|---|---|
| Claude Mythos Preview | Restricted | 93.9% | n/a | Not GA |
| GPT-5.5 | Frontier | 88.7% | $3.00 | Included in ChatGPT Plus |
| Claude Opus 4.7 | Frontier | 87.6% | $2.75 | Phase 1 default; subsidized in Max |
| GPT-5.3-Codex | Frontier | 85.0% | $1.225 | Review constant; free under ChatGPT Plus |
| GPT-5.4 | Frontier | ~80% | $1.50 | Pre-5.5 mainline |
| Gemini 3.1 Pro | Frontier | 80.6% | $2.10 | >200K context tier |
| DeepSeek V4 Pro Max | Open weight | 80.6% | $0.17 - $0.70 | Promo price through May 31, list after |
| Kimi K2.6 | Open weight | 80.2% | $0.42 | Open weights, MIT-modified license |
| MiniMax M2.7 | Open weight | ~80% | $0.15 | Phase 2 default; FP4 via Together |
| Claude Sonnet 4.6 | Workhorse | 79.6% | $1.65 | Anthropic workhorse; subsidized in Max |
| Qwen3-Coder 480B | Open weight | 67-70% | $0.10-$0.30 | Together available |
| GLM-4.5 | Open weight | 64.2% | $0.10-$0.30 | - |
| GPT-OSS-120B | Open weight (older) | 62.4% | $0.075 | Cost floor reference |
Bolded rows are the models in the recommended workflow. SWE-bench Verified is the most-cited coding benchmark (500 real GitHub issues, scored by patch resolution). SWE-bench Pro is the harder Scale AI variant where models break down on cross-file reasoning; Opus 4.7 leads at 64.3%, GPT-5.5 follows at 58.6%, Kimi K2.6 matches at 58.6%, GPT-5.4 at 57.7%, Gemini 3.1 Pro at 54.2%.
API session cost assumes 300K input tokens and 50K output tokens at a 6:1 ratio, representing a medium-complexity task that touches several files and runs a handful of tools. Session totals scale linearly with codebase size and task complexity, but the ratio holds across most coding workloads.
Subscription paths (Codex on ChatGPT Plus, interactive Claude Code on Max) change the picture substantially for the models they cover, which is why the recommended workflow uses them where they fit.
Three caveats apply to the whole table.
SWE-bench Verified and SWE-bench Pro measure resolution rate on isolated, well-specified GitHub issues, which is not the same as production software engineering. Real codebases have undocumented conventions, partial test coverage, ambient context that lives in commit history rather than files, and stakeholder constraints no benchmark captures.
The agent harness also materially affects outcomes: the same model can shift by 4 to 10 points on SWE-bench Pro depending on whether the agent system manages context retrieval well, which is part of why Claude Code outperforms raw Opus in independent-agent framework comparisons.
And repo familiarity and iteration loops matter more in practice than leaderboard deltas. A model scoring three points higher on Verified may underperform on your codebase because the lower-scoring alternative handles your domain or framework better.
The benchmarks are useful for ruling out the tail. 62.4% is real evidence that GPT-OSS-120B is not the right primary coder when 80%+ alternatives exist at similar cost. They do not replace running candidate models against your own workload before committing. The provider decision and the harness are both optimization variables, and the gains compound, which is why "use OpenCode with a better-than-default primary" beats "use Claude Code with whatever Anthropic gives you" on more than just price.
The cheap-and-good open-weight tier exists in a way it did not twelve months ago. DeepSeek V4 Pro Max, Kimi K2.6, and MiniMax M2.7 all land within a point of Claude Sonnet 4.6 on SWE-bench, verified at $0.15 to $0.70 per session versus Sonnet's $1.65 at API list rates. The price-to-performance argument is no longer "trade quality for cost." It is "the quality is functionally equivalent at the open-weight tier, the cost is materially lower, and you can verify both against your own workload before committing."
The frontier gap is real but lives in a specific place. Claude Opus 4.7 leads SWE-bench Pro by 5 to 10 points over the next-best frontier models. SWE-bench Pro is harder precisely because tasks span more files and require sustained reasoning across longer horizons. That is architectural reasoning. The gap on hard cross-file work is what justifies Opus's premium for the architecture phase. The gap on bounded surgical work, as measured by SWE-bench Verified alone, is small enough that paying frontier prices for routine iteration is leaving money on the table.
A heavy coding day (ten sessions, 3M input and 500K output total) costs roughly $1.50 on MiniMax M2.7 versus $16.50 on Sonnet 4.6 via direct API for what may be functionally equivalent output, and $27.50 on Opus 4.7 for the additional architectural-reasoning quality that bounded iteration doesn't actually need.
The 10x to 20x spread between cheap-OSS-iteration and frontier-API-iteration motivates the architecture: route iteration through the cheap tier where quality is good enough, and route architecture through whatever path subsidizes Sonnet or Opus for your specific use case. Subscription bundling further collapses the spread for first-party paths: Codex on ChatGPT Plus and interactive Claude Code on Max bill effectively at zero marginal per session within their limits.
The Recommended Workflow
The workflow has three layers. Architecture decisions route through a frontier model on a subsidized subscription. Iteration runs on cheap, fast models with their own provider keys. Review is a constant gate above both, doing line-level surgery on whatever the primary produces. Each layer uses a different model class and a different cost structure because each layer asks a different kind of question.
Architecture
Architecture work asks, "How should this system fit together?" Designing the schema, scaffolding the module structure, choosing the interfaces, and picking the data flow. Success requires holding the whole shape in mind. This is where premium model quality earns its premium: Claude Opus 4.7 currently leads SWE-bench Verified at 87.6% and SWE-bench Pro at 64.3%, both above generally available alternatives. For decisions that cascade through everything you build on top of them, the differential is the point.
The cheapest path to Opus quality is interactive Claude Code on Max 5x at $100/month, which gives the first 20% of weekly allowance as Opus before auto-switching to Sonnet. Architecture sessions are sparse by their nature, so 20% Opus on Max 5x is functionally unlimited for this layer. The Interactive Claude Code will remain in the subscription rate-limit pool, unaffected by the June 15 credit pool change.
Iteration
Iteration work asks "implement this piece, fix this bug, extend this feature." Bounded scope. Existing code. The model is doing surgery on the architecture you scaffolded. This is the high-volume phase where most sessions live and where model quality matters less per session because the surface area of each task is smaller.
OpenCode replaces Claude Code for this layer. Not a clone: same workflow pattern, but exposes the provider layer so you choose the model, see the cost, and switch configurations by task.
Default: Together MiniMax M2.7 FP4 ($0.15 per session). MiniMax M2.7 is an open-weight coding model; FP4 refers to the 4-bit quantization that makes it cheap to run at scale through Together's hosted API. Roughly 80% on SWE-bench Verified, comparable to Sonnet 4.6. Tool calling works reliably. At $4.50 per 30-session day, sustainable for full-time use without thinking. GPT OSS 120B is half the cost ($0.075) but lands at 62.4% on Verified, so the doubling buys a 17-point quality jump worth it for primary coding work.
Large codebase: Gemini 2.5 Flash ($0.075 per session). When context size becomes the binding constraint, the 1M-token window matters more than per-session cost. In a 150-file service, the agent holds every file, the full test output, the recent git diff, and the schema definitions simultaneously. Smaller-context models on the same task show invisible drops in accuracy, with frequent wrong choices.
Long-running agents and aggressive frontier-tier pricing: xAI Grok 4.3 ($0.50 per session). Grok 4.3's API pricing is $1.25 per million input tokens and $2.50 per million output tokens, which works out to roughly $0.50 per session. That comes in 5x cheaper per session than Opus 4.7, 6x cheaper than GPT-5.5, and 2-4x cheaper than Gemini 3.1 Pro at frontier-tier quality. If you're doing this work full-time, you're probably running 300+ sessions per month, and the savings compound to $600-$750/month over frontier alternatives. AIX offers up to $175/month in free API credits through its data-sharing program, the most generous free tier among major providers.
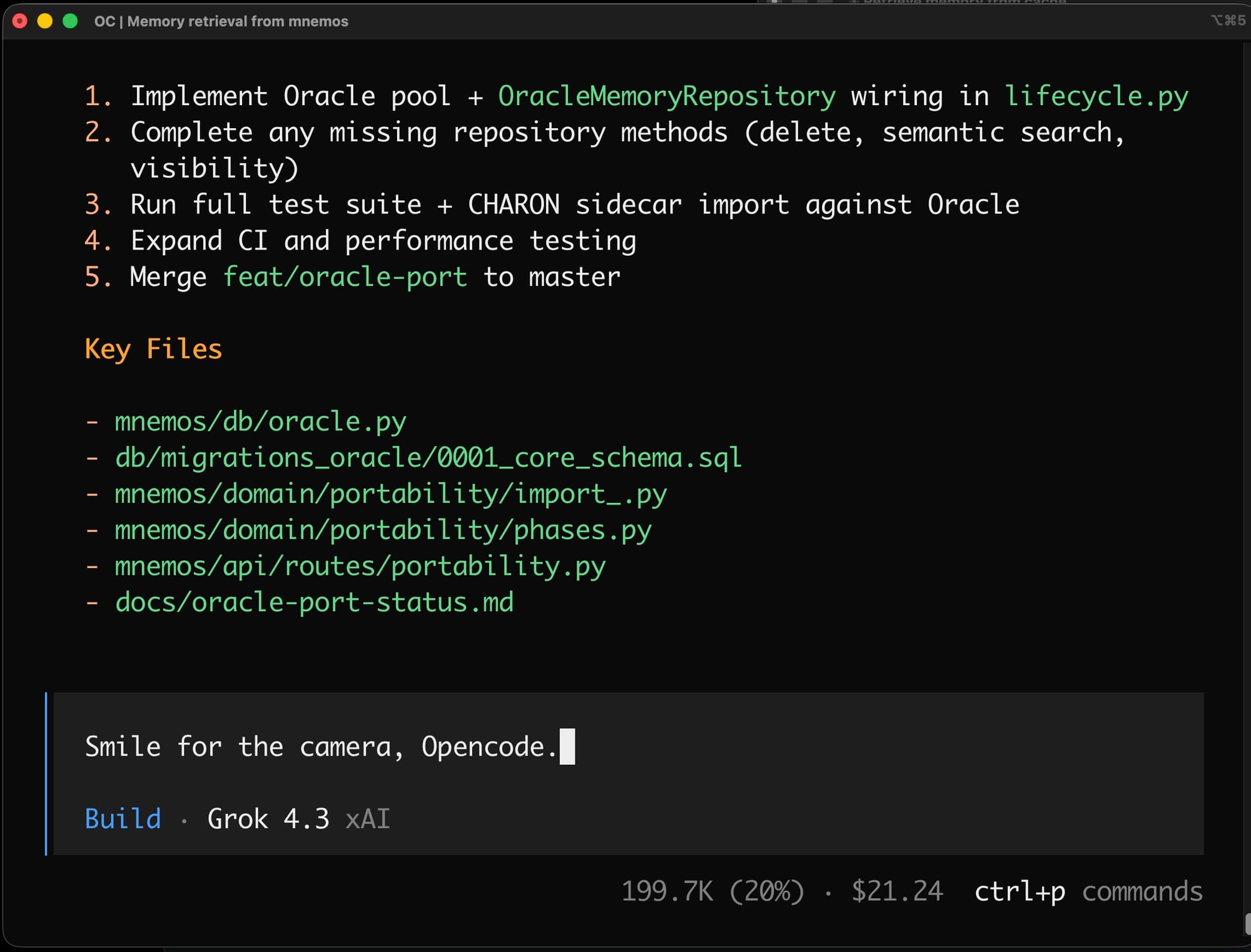
On performance, Grok 4.3 trails Opus on the standard SWE-bench by ~14 points, but outperforms by 1.5-2x on xAI's published Vending-Bench numbers, which measure sustained coherence over many hours of continuous operation rather than single-task accuracy. I have been using Grok 4.3 to port MNEMOS from Postgres/pgvector to Oracle 26ai, which clearly surfaces the model's profile.
When latency matters, Groq returns tokens at 500-1000 per second versus the 80-100 per second I see on typical OpenAI endpoints in practice. For iteration sessions with many short tool calls, the difference is ninety seconds versus fifteen. Groq Compound is the path when speed and tool calling are required.
Review
Review is the constant gate above both layers. Claude scaffolds, OpenCode iterates, ChatGPT Codex reviews and patches both outputs. The primary rotates by phase. The reviewer does not.
Think of Codex as surgeon, not architect. Bounded scope, clear success criterion. Codex's 85% SWE-bench Verified score reflects what it is actually good at: precise interventions on existing code where the problem statement is concrete and the gold-standard fix is recognizable. The constant-Codex-rotating-primary pattern works because the review-and-fix loop is the same operation whether the primary just scaffolded a new module or iterated on an existing one.
Primary coder (Claude or cheap OSS) → diff / initial output
↓
Codex review + fix in place → hardened, final output
When work hands off to Codex, Codex patches in place rather than handing flagged issues back. Review and fix run inside the same cloud task. Codex already has the diff, the findings, and a 400K context window. Routing fixes back through the cheap primary means re-loading context and translating review notes into patches, which is work the higher-capability model is better positioned to do directly.
The economics work because of subscription coverage. The gpt-5.3-codex API at $1.75/$14 per 1M would run ~$0.18 per session at primary-coder volumes, more than twice MiniMax for not enough quality lift to justify the premium on routine iteration.
As a bounded reviewer running once per session, the same model is essentially free under ChatGPT Plus at $20/month, with a 2x usage promotion through May 31, 2026 as of this writing. Extrapolating from Pro 5x's published 10-60 tasks per 5-hour window at 1/5 the allowance, Plus comfortably handles roughly 5-25 Codex cloud tasks per 5-hour window. Marginal cost of a review within the subscription is effectively zero.
OpenCode does not yet support multi-model session routing natively, so the pattern requires a separate review invocation:
# Primary coding session on cheap model
opencode --model together/minimaxai/minimax-m2.7-fp4
# After session, review and fix in place via Codex
codex "review this diff for bugs, security issues, and test gaps. fix issues in place." < diff.patch
The Two-Pool Structure (and Why Most Developers Get This Wrong)
Most developers reading this far have probably internalized "interactive vs programmatic" as the dividing line between what's covered by their Claude subscription and what gets metered against the new Agent SDK credit. That framing is wrong. Missing the actual rule makes the recommended workflow harder to evaluate, and it sends people toward configurations that drain the credit fast.
The real rule: authentication target determines billing pool. Not whether a human is at the keyboard. Not whether the agent runs autonomously or under your direct prompting. The question Anthropic's billing system asks is who built the client and what auth path it takes.
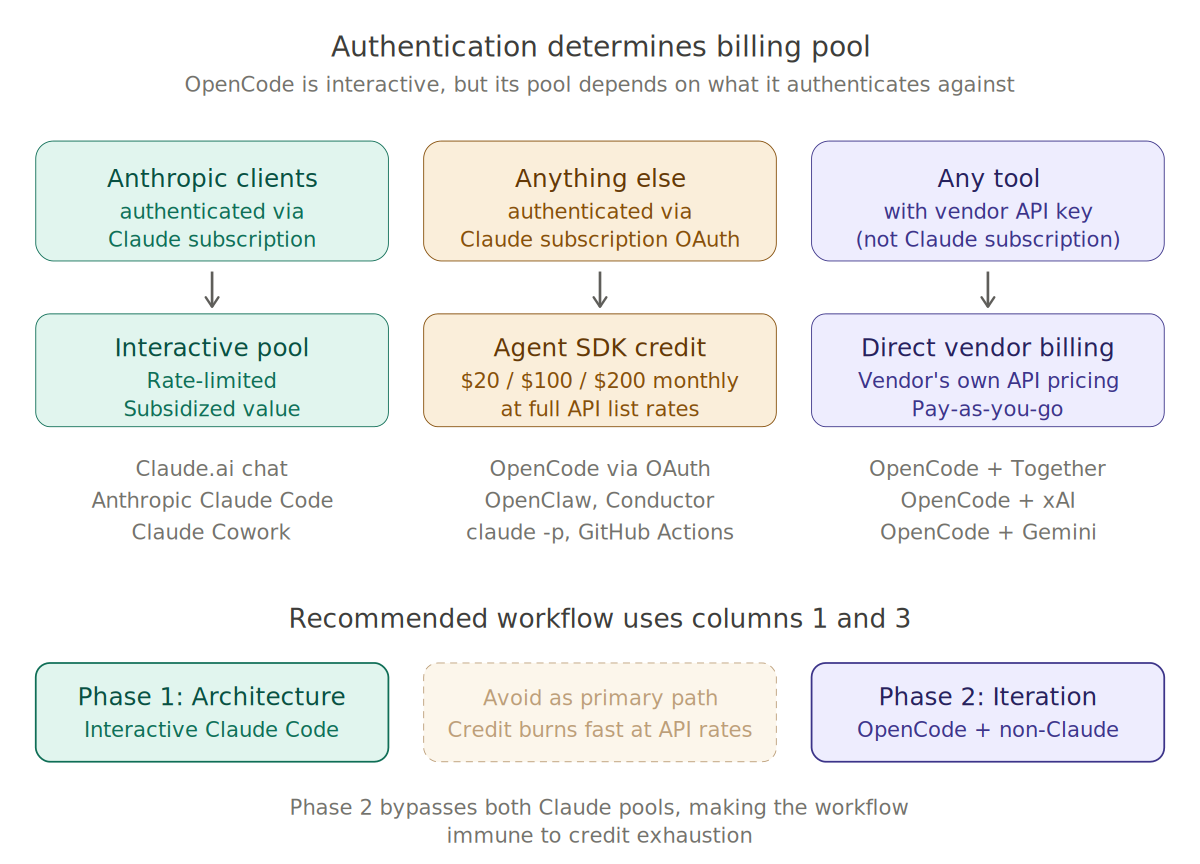
Figure 1. Authentication determines which billing pool a coding session draws from. The recommended workflow uses Columns 1 and 3, bypassing the credit pool entirely.
OpenCode is the test case that breaks the interactive-versus-programmatic intuition. It is terminal-native, agentic, reads files, writes edits, iterates exactly like Anthropic's own Claude Code. You sit at the keyboard. A human is in the loop. By every functional test it looks identical.
But OpenCode pointed at Claude via OAuth lands in the Agent SDK credit pool. OAuth here refers to the login flow OpenCode uses to authenticate with your Claude subscription, analogous to "Sign in with Google" elsewhere on the web. Anthropic's billing system classifies any non-first-party tool authenticated that way as Agent SDK use. The workflow's interactive nature does not matter to the billing engine. The auth target does.
Phase 1 (interactive Claude Code) lives in Column 1, drawing from the rate-limited interactive pool with subsidized economics. Phase 2 as recommended in this piece (OpenCode plus Together, xAI, or Gemini directly with those vendors' own API keys) lives in Column 3, paying those vendors at their published rates and never touching either Anthropic pool. Both phases avoid Column 2, where most developers' OpenCode-plus-Claude setup would land if they had not considered the auth path.
The June 15 change makes this distinction operationally consequential. Pre-June 15, OpenCode pointed at Claude via OAuth drew from the same subscription pool as interactive Claude Code, just with different cache-hit efficiency. Post-June 15, that path is metered against a finite dollar credit at full API list rates.
The credit dollar amount matches the subscription dollar amount: $20 for Pro, $100 for Max 5x, $200 for Max 20x. [TK: link to Anthropic announcement.] No leverage. No subsidy. The arbitrage that previously let a Pro subscription drive several hundred dollars of OpenClaw-equivalent agent value per month is over.
If the agent credit is included in your subscription regardless of whether you use it, what is the best way to actually use it?
As of May 19, 2026, xAI shipped its own parallel subscription-OAuth structure. SuperGrok ($30/month) and X Premium ($8/month) subscribers can now authenticate Grok 4.3 inside OpenClaw via OAuth, with $0 per-token cost for chat (subject to a hard cap of roughly 50 to 100 messages per 2 to 3 hour window) and server-side tool calls (web search, code execution) billing separately at $5 per 1000 calls.
The mechanic is structurally identical to what Figure 1 describes for Anthropic, with materially different operational characteristics: xAI's path is flat-fee rate-limited where Anthropic's is dollar-metered at API list.
The three-lane structure is no longer Anthropic-specific. It is an industry pattern that two of three major frontier vendors have now shipped within sixty days of each other, and the auth-determines-pool insight applies to both with the same force.
Right-sizing the Anthropic Tier
If you are running Max 20x at $200 per month, the question is whether you actually need that much Claude allowance once Codex on Plus and OpenCode are handling parts of the load. The Anthropic pricing tiers are not as different in practice as they look on paper.
| Tier | Cost | Messages / 5hr | Weekly Sonnet hours | Opus availability |
|---|---|---|---|---|
| Pro | $20 | ~90 | ~28-56 | None (extra credits required) |
| Max 5x | $100 | ~450 | ~140-280 | First 20% then auto-switch to Sonnet |
| Max 20x | $200 | ~1,800 | ~560-1,120 | ~80% before auto-switch |
The constraint that actually binds on Max plans is Opus availability, not Sonnet time. Max 5x gives you the first 20% of your weekly allowance as Opus, then auto-switches to Sonnet. Max 20x gives you roughly 80%. Sonnet capacity at either tier is well beyond what a single developer can exhaust on routine work.
For the two-phase workflow, where architecture is sparse and high-leverage and iteration is the volume tier handled by OpenCode, 20% Opus on Max 5x is functionally unlimited. Architecture sessions do not generate the sustained token burn required to exhaust allocations.
The $ 80-per-month difference between Max 5x and Max 20x covers approximately 160 Grok 4.3 sessions at $0.50 each, or 533 MiniMax M2.7 sessions at $0.15 each. If your iteration volume is anywhere near that range, the downgrade is mathematically favorable. You spend the same total dollars, you keep Opus for architecture, and you trade a Claude rate-limit ceiling for an unbounded iteration tier with explicit cost transparency.
The one scenario where staying on Max 20x continues to make sense: architecture-phase Opus usage that regularly exceeds 20% of the Max 5x weekly allowance. The empirical way to check is Claude Code's /status command, which displays current window utilization. If your Opus usage sits at 15% or higher of the Max 20x window, downgrading would put you against the auto-switch threshold. If it is below that, you are paying $100 per month for Opus capacity you do not consume.
Putting the Agent SDK Credit to Work
If you have a Max subscription and you are not running OpenClaw, Conductor, or another headless harness that requires the Agent SDK path, the credit is unused capacity on your subscription each month.
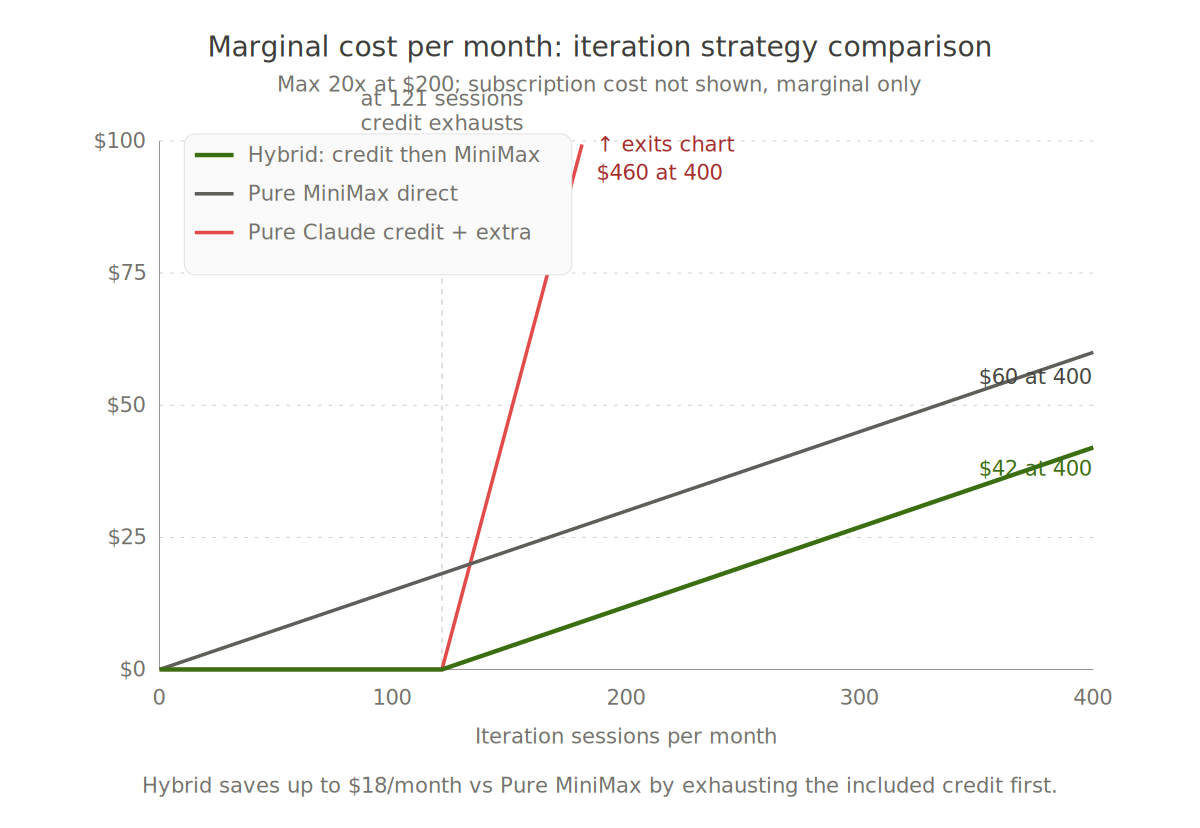
Figure 2. Marginal cost per month for three iteration strategies on Max 20x at 300+ sessions/month. Hybrid covers the first 121 sessions free of charge, then reverts to MiniMax. Pure credit becomes a trap past exhaustion because extra usage bills are at API list rates with no subscription discount.
Option 1: Hybrid primary. Configure OpenCode to point at Claude via OAuth for iteration. The $200 Max 20x credit covers the first ~121 Sonnet sessions/month at $0 marginal cost, then switch to MiniMax M2.7 when the credit runs dry. Saves ~$18/month at Max 20x versus pure MiniMax. The operational tax is a config swap or a script against /usage that flips the model at exhaustion. At Max 5x with a $100 credit, savings drop to ~$9/month, which is below the operational threshold for most readers. The red line on the chart shows what happens if you do not swap: pure-credit-with-extra-usage exits the chart ceiling at session 181 and reaches $460 marginal at 400 sessions, because extra usage bills at API list with no subscription discount.
Option 2: Adversarial review layer. Route the credit as a second-stage reviewer above Codex rather than as a primary. Codex catches and fixes bugs (line-level surgery). Claude flags design issues that compile but are poorly designed (architectural critique). Different review tasks, different model shapes, complementary. The economics work because review sessions are bounded: ~100K input + ~10K output per review runs ~$0.45 on Sonnet or ~$0.75 on Opus. A $200 Max 20x credit buys 444 Sonnet reviews or 266 Opus reviews per month, enough to review every iteration session and have credit to spare at 300 sessions. The workflow adds one command after Codex:
opencode --model anthropic/claude-opus-4-7 \
"Review this diff for architectural issues, code smells, design problems, and drift from the architecture plan. Don't refactor. Flag and explain." < diff.patch
The choice depends on what you value more. Hybrid primary saves $18/month on raw compute. Review layer adds a capability that the OSS-plus-Codex stack does not have. Same credit budget, so picking one is honest.
Practical Configuration
Total monthly cost for the recommended workflow at constant-churn volume (roughly 300 iteration sessions per month):
| Component | Cost |
|---|---|
| Claude Code Max 5x (Opus for architecture) | $100 |
| ChatGPT Plus (Codex review, both phases) | $20 |
| OpenCode + MiniMax M2.7 × 300 sessions | $45 |
| Total | $165/month |
Substitute Grok 4.3 for context-bound or long-running iteration work at $150/month for 300 sessions, putting the total at $270. Substitute Pro for Max 5x if Sonnet-only architecture work is sufficient at $20/month, putting the total at $85 (but you lose Opus access).
OpenCode configuration:
// ~/.config/opencode/opencode.jsonc
{
"$schema": "https://opencode.ai/config.json",
// Default iteration: best quality at lowest cost
"model": "together/minimaxai/minimax-m2.7-fp4",
// Override for large codebase work (1M context):
// "model": "google/gemini-2.5-flash",
// Override for long-running autonomous agents:
// "model": "xai/grok-4.3"
}
The Codex review loop:
codex "review this diff for bugs, security issues, and test gaps. fix issues in place." < diff.patch
ChatGPT Plus at $20 per month provides the Codex adversarial review path. No need to step up to Pro at this volume.
The Larger Pattern
The pattern this piece has been describing under the cost analysis is now visible in market structure. Frontier reasoning is becoming a sparse premium resource. High-volume implementation work is becoming commoditized. Open-weight coding models have closed the gap to Sonnet-class quality at one-tenth the cost.
Codex is best as a precision tool, not a primary coder. Grok 4.3 is best as a long-chain agent and as the most aggressively priced frontier-tier reasoning option, not a benchmark champion. Each tier of work is finding its model rather than each model trying to be universal.
Subscriptions stop being primary compute sources and start functioning as routing layers. You pay Anthropic $100 a month to access Opus capacity for the moments that need it. You pay OpenAI $20 a month for Codex review tasks that gate everything else. You pay Together or xAI per-token for volume work, because it'sthat now cheap enough that per-token billing is sustainable for a single developer.
The optimal stack is heterogeneous by default because no single vendor competes effectively across all three roles, and the pricing structures of every major vendor reward exactly that pattern.
The Grok 4.1 Fast SKU at $0.20 input and $0.50 output per million tokens was the workhorse iteration tier that on June 6 alongside IBM's next release, which usesthe original February article recommended. xAI deprecated it on May 15, redirecting workloads to Grok 4.3 at $1.25 input and $2.50 output per million tokens, structurally identical use case at roughly 5 to 6x the cost. Four days later they shipped the OAuth subscription path.
The sequence is consistent: lock in the developer cohort at an aggressive per-token price, deprecate the SKU, redirect to a higher-priced successor, then offer a subscription path that flattens the per-token complaint for the cohort most likely to switch providers. Anthropic's June 15 change is the same playbook executed in different denomination.
The products exist now. The pricing trajectory and the deprecation-redirect mechanic suggest the underlying gap is durable even when specific SKUs come and go.
The recommended architecture in this piece is designed to be robust to that trajectory. Keeping iteration on non-Claude vendor API keys or open-weight models means the workflow does not depend on any single vendor's pricing remaining stable, and adding the architect-reviewer layer through whichever subscription credit is included means the value capture flows toward bounded high-leverage tasks rather than high-volume metered ones.
If you're running agentic coding as a primary workflow, the configuration question is the one that matters, and the answer is in the sections above. Neither the June 15 Anthropic change nor the May 19 xAI announcement solves the economics. They confirm the categorization that justifies the architecture: agentic work is structurally different from chat, and is being priced as such. The piece you just read describes one defensible response. There will be others. Model loyalty is not the right optimization. Workload fit is.
I shipped Oracle 26ai support for MNEMOS today (May 19, 2026). The iteration work ran on xAI Grok 4.3, scaffolded by Claude Opus and Sonnet architecture sessions in interactive Claude Code. This is the exact workflow described in this piece, used to ship a production release this week, not a theoretical benchmark exercise. DB2 support launches on June 6 alongside IBM's next release, which uses the same stack. The provider configurations described here reflect that actual production work. The Anthropic and employer disclosures from the original article stand unchanged.