Memory is not a feature

Disclosure: This post reflects independent personal experimentation and my own hands-on work on personal open-source projects. It reflects only my personal views, is not professional advice, and does not represent any organization, employer, or official position.
MNEMOS v5.0.1 · Apache 2.0 · In production since December 2025
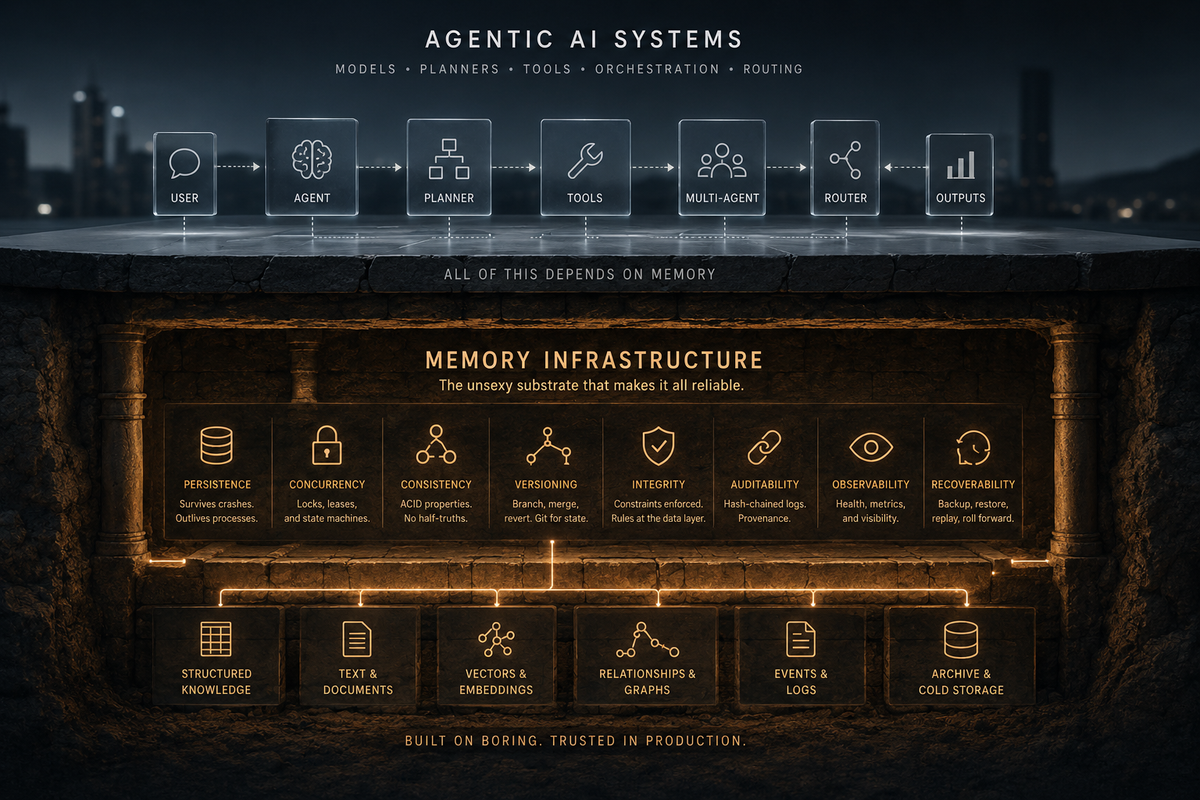
Memory is the least sexy thing in agentic AI. It is also the thing that decides whether your system works.
The exciting work happens elsewhere. Reasoning chains, planner-executor patterns, tool use, multi-agent orchestration, model routing. These are the demos that go viral. Memory shows up in passing, treated as a configuration concern. A vector store. A context window. A summary buffer. A "we'll figure that out later" footnote at the bottom of the architecture diagram.
That footnote is where every serious agentic system goes to die.
I got tired of waiting. Six months ago I started building the memory layer the industry should have shipped years ago. It is in production. It is Apache 2.0. The case for why it had to exist comes first. The thing itself comes at the end.
The diagnosis
Build an agent that can handle a real task end to end. Watch what kills it.
It is not the reasoning. The models can reason. It is not the tools. The tool calls work. It is not the planner. The planner makes plans.
What kills it is that the agent forgets. It forgets between sessions. It forgets across processes. It forgets what it decided two hours ago. It forgets which provider it failed over from. It forgets the constraints you spent an hour establishing.
Then it does worse than forgetting. It half-remembers. The summary buffer compressed a critical detail away and the agent now confidently believes the wrong thing. The vector store returned the closest match in embedding space, which happens to be from a different project, and the agent acts on it. The context window filled up and silently truncated the part you actually needed. The agent's "memory" is now a confidently held set of false beliefs, and there is no way to tell which beliefs are intact and which are corrupted.
This is the part nobody wants to write about. The failure mode is not a hallucinated fact. It is a structurally unreliable substrate underneath an otherwise capable model.
Let me name the fallacies, because the industry treats them as solved problems.
Conversation history is not memory. It is a transcript. It records what was said. It does not represent what was learned, what was decided, what was rejected, what is still under consideration.
A big context window is not memory. It is working set. Working set is bounded, expensive, and ephemeral. Treating it as memory is the same category mistake as treating RAM as a database. You will get away with it for a while. Then you will not.
A vector store is not memory. It is a retrieval mechanism over embeddings. Embeddings approximate semantic similarity. Similarity is not relevance. Relevance is not truth. A vector store will return the nearest neighbor whether or not that neighbor is the thing you needed, whether or not it is current, whether or not it is contradicted by something else in the store.
A summary buffer is not memory. It is a lossy compression with no manifest. You do not know what it dropped. You cannot recover what it dropped. If a regulator asks how your agent arrived at a decision, "we summarized it" is not an answer.
"We will figure that out later" is not memory. It is the most common architecture pattern in the industry right now, and it ships systems into production with no plan for the part that actually matters.
The failure modes follow.
Context loss at the process boundary. Session ends, process restarts, the agent's working understanding is gone. The next run reconstructs from scratch and gets it slightly wrong.
Silent compression failure. The summary kept the wrong things. You will not know until the output is published, the trade is placed, the patient advised.
Multi-agent drift. Two agents working the same problem develop different beliefs because they have separate memory pools. The orchestrator merges their outputs and produces something internally inconsistent.
Audit gap. A decision was made three months ago. The reasoning chain is gone, the cited sources were not stored, the model has been deprecated. Nobody can reconstruct the answer.
Provider cascade. The LLM provider has an outage. Reasoning stops because the memory layer has no fallback. Single point of failure inside a system you thought was distributed.
Fabrication under uncertainty. The agent cannot find the answer and proceeds anyway. You cannot tell whether the output was grounded or invented. There is no provenance.
All of these have a single root cause. The memory layer is not infrastructure. It is an afterthought.
The forgotten -ilities
I have been around long enough to find this funny.
I started building systems for banks, insurance companies, and government agencies, where the database was the entire universe and the application was the part you wrote on top of it. The first question on any new project was not "what does the app do." It was "what is the data model." The data model would outlive the app, the team, and the company that bought the company that bought your company.
Those systems had a vocabulary. The AI industry has decided to forget it.
Atomicity. A write either completes or it does not. There is no half-written state visible to other readers. If the storage failed, it failed cleanly. It did not leave a half-formed memory behind that the next reader will treat as real.
Idempotency. The same operation, performed twice, produces the same result as performed once. The retry does not produce a duplicate. The retry does not corrupt the original. The retry is safe by design.
Referential integrity. Relationships are enforced by the data layer, not hoped for by the application. The rules are not in your application code where the next contractor can violate them. They are in the database, which will refuse to violate them.
ACID. The four properties that distinguish a database from a folder full of text files. If your memory layer does not provide them, it is a folder full of text files. You will discover this the first time two writers race.
Durability. A confirmed write survives a crash. A memory layer that loses confirmed writes is a memory layer that loses memories.
Recoverability. You can restore from backup. You can replay from a known good state. You can roll forward through the log. The system was designed to be restored, not just to be backed up.
Observability. You can see what is happening inside the system without changing the system. The memory layer reports its own health. It does not require you to deduce its state from external symptoms.
Auditability. Every state change leaves a record. The record cannot be silently edited. You can prove what the system did, when, on whose authority, with what inputs.
Testability. The system can be exercised under controlled conditions. Failure modes can be reproduced. Behavior under load is known, not guessed.
None of this is glamorous. None of this would make a YouTube thumbnail. None of this is what you talk about at the AI conference where everyone is comparing benchmark scores.
All of it is what the difference between a demo and a production system actually consists of.
I did fifteen years of standardize-consolidate-reduce-outsource work at IBM and Unisys and Microsoft. I watched bank after bank build their reliability on top of these properties. I watched the same kind of company lose a quarter's revenue when somebody tried to skip them. The lessons were paid for. They are in the literature. They are in the standards. They are in the textbooks that the people writing agentic AI frameworks did not read because the textbooks were boring.
The textbooks were boring on purpose. Boring is what reliable looks like from the outside.
You cannot read your way to this. You can read about transaction isolation levels and not know in your gut which one matters until you have shipped the wrong one and watched the production incident unfold. You can read about referential integrity and not understand why ON DELETE CASCADE on the wrong edge is a career-shortening mistake until you have done it. You can read about hash-chained audit logs and not appreciate why advisory locks around the chain tip are non-negotiable until you have seen what two concurrent writers do to a TOCTOU window under regulatory review.
The operational scar tissue is the product. The literature is the index. The architecture is the synthesis. You can build a vector store with six months of experience. You cannot build memory infrastructure with six months of experience, because you do not yet know which six things are going to bite you, in what order, and how loudly. The people who can architect substrate are the people who have already lost the arguments and shipped the fixes. The industry has spent a decade telling those people they were obsolete.
They were not obsolete. They were early.
What memory infrastructure actually has to do
If memory is infrastructure and not a feature, the next question is what infrastructure for memory has to provide. Here is the floor.
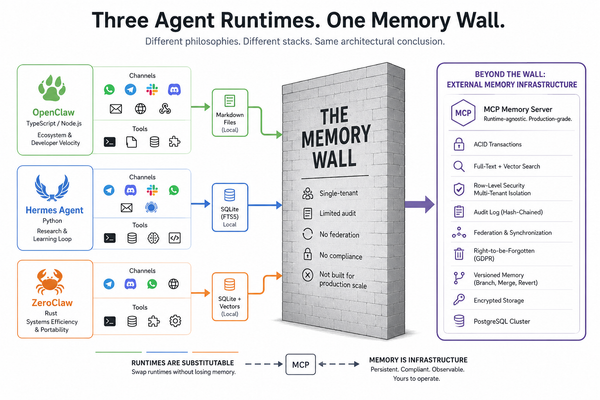
Persistence that survives the process lifecycle. The memory layer is a service. It runs in its own process. When the agent crashes, the memory does not crash. When five agents need the same memory, they talk to the same memory layer over a stable network protocol, not five copies of the same library reading and writing to five potentially divergent stores.
Multi-tenancy with real isolation. Owner identity, namespaces, and permission modes enforced at the data layer. The application cannot accidentally grant access it should not have granted because the database will refuse the read. Row-level security is not aspirational. It is the floor.
Compression as an audited operation. When a memory is compressed to fit in a context window, the system must record what was removed, what was preserved, the rationale, and what use cases the compressed version is and is not safe for. Compression without a manifest is data loss, full stop.
Versioning that lets you go back. Memory mutates. The old version does not vanish. You can diff. You can revert. You can branch and merge. This is git for state. The fact that we built git for code thirty years ago and have not built it for agent memory is an embarrassment.
Foreign keys with deliberate ON DELETE semantics. Every cross-table reference has an explicit rule. Some cascade. Some nullify, because the audit record must outlive the artifact. Some restrict. The constraint travels with the row.
Concurrency primitives that survive multi-worker deployments. Real systems run multiple workers. Real workers race. The memory layer must use advisory locks, terminal triggers, leases, and persisted state machines so that when two workers try to do the same thing at the same time, exactly one wins and the loser fails cleanly. This is the unglamorous code that makes everything else possible.
Hash-chained audit logs that survive review. Every consequential operation recorded. Every record cryptographically linked to the previous. The chain cannot be silently rewritten. If your audit log can be edited by anyone with database access, you have a log, not an audit chain.
Reasoning that degrades gracefully. A memory layer dependent on a single LLM provider is one outage away from useless. Route across providers, track per-provider health, weight by quality, fall back when a provider goes down. The boring distributed-systems patterns from the microservices era apply directly. The industry skipped them and is rediscovering them.
Structured knowledge alongside text. Free-text memory is necessary. It is not sufficient. Real systems also need structured facts: subject, predicate, object, with temporal validity windows. The knowledge graph and the text store sit next to each other and are joined when needed.
Federation for remote data flows. Replication for high availability. These are different problems. Replication is what you do when you want the same data on two machines at the same site, and it is solved at the database layer with streaming WAL. Federation is for genuinely remote sites with separate trust boundaries and intermittent connectivity. Confusing the two leads to baroque architectures.
Hot path performance. Vector math, top-k retrieval, cosine similarity. These get called millions of times in a production system. Pure Python is fine for a prototype. Pure Python is not fine for a substrate. The hot operations belong in compiled code with deterministic semantics and a fallback path that produces identical results.
Deployment topologies that match where the work runs. Production servers backed by Postgres and Redis. Developer laptops. Raspberry Pis at the edge. The memory layer must support all three without forcing a rewrite. Same API. Same semantics. Different backends. One contract.
This is not exhaustive. It is the floor. Below this floor, you do not have memory infrastructure. You have a vector store with ambitions.
MNEMOS
I built it.
The project is called MNEMOS. It has been in daily production use since December 2025, backing multiple agentic systems simultaneously. The current public release is v5.0.1. The license is Apache 2.0. The repository is at github.com/mnemos-os/mnemos.
I am the only author. The work was pair-coded with agentic AI, which is the appropriate irony: the substrate that makes agents reliable was built by an agent and the operator pushing it.
What pair-coding does not do is supply the operational priors. The model can write the advisory lock. The model cannot tell you that you need one until you tell it you need one. The model can implement the foreign key. The model cannot tell you which ON DELETE semantic the audit chain requires until you explain that the audit record must outlive the artifact. The model can build the retry state machine. The model cannot tell you that the state machine needs a terminal trigger at the database layer because application-only enforcement will eventually be defeated by a stale writer. Every load-bearing design decision in MNEMOS was made by someone who had seen the failure mode before. The agent accelerated the typing. The architecture is the synthesis of thirty years of watching what breaks.
What MNEMOS actually is, in v5.x:
A FastAPI service on port 5002 with three deployment profiles. The server profile uses PostgreSQL with pgvector and Redis-backed shared coordination across workers. The edge profile uses SQLite with sqlite-vec in a single process, suitable for a laptop, a Pi, or a phone-adjacent install. The dev profile is edge with debug logging. Same contract, different backends, picked at install time.
A persistence abstraction that owns the contract independently of either backend. Postgres uses asyncpg, pgvector, row-level security, and LISTEN/NOTIFY for write fanout. SQLite uses aiosqlite, sqlite-vec, FTS5, JSON1, and WAL journaling. The application code does not branch on which backend is in use. It calls the contract.
The MOIRAI compression subsystem. Compression runs as an operator-batched contest between engines. The built-in stack is APOLLO, a schema-aware dense encoder for LLM-to-LLM wire format, and ARTEMIS, a CPU-only extractive compressor with identifier preservation. Every eligible memory runs through every applicable engine. The winner is chosen by composite score. The losers are persisted with their scores and rejection reasons. Every transformation produces a manifest: what was removed, what was preserved, the quality rating, the risk factors, the safe use cases, the unsafe ones. Compression without a receipt is not the contract.
The GRAEAE reasoning bus. Multi-provider routing with consensus modes. Per-provider circuit breakers, three-state machine, five-minute cooldown. Quality scoring on relevance, coherence, completeness, and toxicity. Semantic cache on identical prompts. Arena.ai Elo rankings folded into per-provider weights through a self-populating model registry. SHA-256 hash-chained audit, owner-scoped, externally verifiable.
MORPHEUS, the divergent dream-state pipeline. Replay, cluster, consolidate, synthesise, extract. Operator-triggered, not an automatic mutation daemon. Every generated memory tagged with its run, so the run can be rolled back without leaving orphans. PERSEPHONE archives rarely-recalled memories into a zstd-compressed cold table with a live-table stub pointer, restorable on demand. KRONOS does recall observability: z-score anomaly detection over recall history, namespace drift detection, EWMA recall-load forecasting, archival eligibility forecast. PANTHEON is the unified LLM facade with OpenAI-compatible endpoints, an auto-populated provider catalog, alias prefix routing (auto:reasoning, auto:cheap, auto:fast, consensus:<task>), per-user caps, and rolling-window adaptive routing.
DAG versioning on every memory. Log, branch, merge, revert. Every mutation auto-snapshots. Branch writers refuse cross-memory parent edges through a trigger that raises a specific error. Concurrent merges and reverts on the same branch serialize through advisory locks. Git for state.
A 23-tool MCP registry shared by both the stdio and HTTP/SSE transports. Drop MNEMOS into Claude Code, OpenClaw, ZeroClaw, Hermes, or any other MCP-aware client and the agent gets persistent memory without the framework needing to know MNEMOS exists. An OpenAI-compatible gateway at /v1/chat/completions and /v1/models for SDK clients: memory injection, multi-provider routing, propagated generation controls, streaming SSE, and explicit 400s when a provider cannot honor a requested feature. Silent dropping of unsupported features is how systems lie to their callers. A bridge family for surfaces that do not speak MCP natively (openai, gemini, anthropic, aider, crewai, claude-connector), translating MCP tool definitions into each target SDK's tool-call shape.
Webhooks with durable delivery, HMAC-SHA256 signatures, persisted leases, terminal triggers at the database layer, recovery workers, advisory-lock-serialized chain finalization, and SSRF-hardened dispatch with re-validation at send time. The retry state machine is paragraphs of work. It exists because the alternative is silent message loss.
Federation between genuinely remote MNEMOS instances. Pull-based one-way sync with mutual Bearer-token trust, dedup on stable federated IDs, opaque compound cursoring that cannot skip rows when many share an updated timestamp, namespace and category filters, loop prevention by source attribution, per-memory size caps. CHARON, the federation schema-compat preflight, runs before any sync attempt. Peers exchange schema signatures and refuse incompatible migration sets with an explicit 409 rather than silently corrupting each other downstream. CHARON does not show up in feature lists and is the difference between federation that works in production and federation that produces silent data drift between instances at slightly different versions. It is the schema version handshake. It is forty years old. It is non-negotiable.
OAuth and OIDC alongside API keys, with database-backed revocable sessions. A GDPR right-to-be-forgotten worker with a five-phase lifecycle and a thirty-day restore window. Trigger-suppressed hard delete preserves the audit chain.
A Rust hot-path accelerator at v0.2. Cosine, top-k, batch cosine, embedding parse, L2 normalize, composite re-rank, deterministic judge scoring, SHA-256 batch hashing. Opt-in with an environment flag. Identical Python fallback when the accelerator is not built. The substrate has to perform, and the substrate has to fall back. Both.
Single-binary distribution for linux-x86_64, linux-aarch64, and macos-aarch64 with sqlite-vec bundled. No host Python required. Seven import-linter contracts in CI enforce the package architecture. 1055 unit tests with integration tiers for cross-namespace isolation, multi-worker smoke, and Postgres-versus-SQLite parity.
This is what six months looks like when you are doing the work nobody wants to do, because the work nobody wants to do is the work that makes everything else possible.
The gift
MNEMOS is Apache 2.0 because that is the only license that makes sense for substrate.
Two kinds of work are happening in agentic AI right now. One is building reasoning models. That work is venture-funded, capital-intensive, and competitive the way a chip foundry is competitive. Companies, revenue models, leaderboards. The competitive dynamic fits.
The other is building the substrate that makes the models useful in production. That work is time-intensive and craft-intensive. It looks like database engineering and distributed systems engineering and the careful application of patterns that have been in the literature for forty years. It should not be venture-funded and proprietary, for the same reason PostgreSQL is not venture-funded and proprietary. The substrate of a healthy ecosystem is the commons. Memory layers should commodify into a contract that everyone can build on and nobody owns.
MNEMOS is my contribution to the commons. It interoperates with every major agent framework on purpose. It uses MCP because MCP is the right wire protocol for tool-shaped memory operations. It uses OpenAI-compatible REST because that is what every SDK already speaks. It exposes a native v1 surface for clients that want to talk to it directly. It does not lock you into a runtime. It does not lock you into a framework. It is the layer beneath the layer.
If you are running agents in production and your memory layer is a vector store and a summary buffer, you are building on sand. The failure modes are not exotic. They are inevitable. The question is how much work you will have rebuilt by the time you decide to take memory seriously.
If you are building agent frameworks and you ship your own memory implementation, consider whether you should. The framework's job is orchestration, planning, tool dispatch. The memory's job is the substrate. They are not the same job. They do not need to be in the same repository. They probably should not be.
If you are an operator deciding what to install, install something with the -ilities thought through. Install something with explicit foreign keys, hash-chained audit, persisted state machines, and a written manifest on every compression. Install something that has been in production for months, not weeks, with a public commit history. Install MNEMOS, or install something better than MNEMOS, but do not install something less.
The exciting work in agentic AI gets the credit. The substrate work keeps the system running while the exciting work is happening. Both are necessary. Only one of them is being done seriously enough right now.
Take memory seriously. Or watch your agents keep losing it.
Get MNEMOS
Source, documentation, and issue tracker: github.com/mnemos-os/mnemos
Bridge packages for non-MCP surfaces: gitlab.com/mnemos-os
License: Apache 2.0
Current release: v5.0.1
Install via pip:
pip install 'mnemos-os[edge]==5.0.1'
mnemos serve --profile dev
Install via Docker:
docker pull ghcr.io/mnemos-os/mnemos:5.0.1
Single binary, no host Python:
curl -L https://github.com/mnemos-os/mnemos/releases/download/v5.0.1/mnemos-linux-x86_64 -o mnemos
chmod +x mnemos
./mnemos install --profile edge
./mnemos serve --profile edge