Beyond the Demo: What It Actually Takes to Build a Production-Grade Agentic Skill


Disclosure: This reflects my personal experience and interpretation of publicly available information. All product evaluations are based on my own hands-on testing in the context of personal agentic skill development — not general benchmarking, sponsored evaluation, or professional recommendation. It represents my views alone — not any employer or organization — and is not professional, financial, or investment advice.
When I published my last piece on OpenClaw backend optimization, I had a working agent framework and a battle-tested model selection. What I didn't have was a skill worth running on it.
Most OpenClaw skills — and, frankly, most agentic skills across any framework — follow the same pattern: take user input, hand it to the LLM, return the response, and call it done. That works fine for a Slack summarizer or a meeting scheduler. It doesn't work for anything that touches money, math, or decisions with consequences.
I wanted to build something that would demonstrate what a production-grade agentic skill actually looks like. The domain was obvious because I was living the problem.
My portfolio is split across three brokerages. Primary broker, Schwab ESPP, Fidelity 401(k). I was using Yahoo Finance to try to consolidate everything into one view, and what I got was a giant wall of numbers that told me nothing actionable. I couldn't walk into a meeting with my financial advisor and have a coherent conversation about what was happening across all three accounts. What I needed was synthesis. Aggregated holdings, cross-account performance, bond analytics, risk exposure. Not a dashboard of raw prices. An analysis I could actually use.
This seemed like the perfect fit for AI. It's data-intensive, stateful, regulation-adjacent, computationally nontrivial, and deeply personal. I went looking for an agentic skill that could do any of this. I didn't find one.
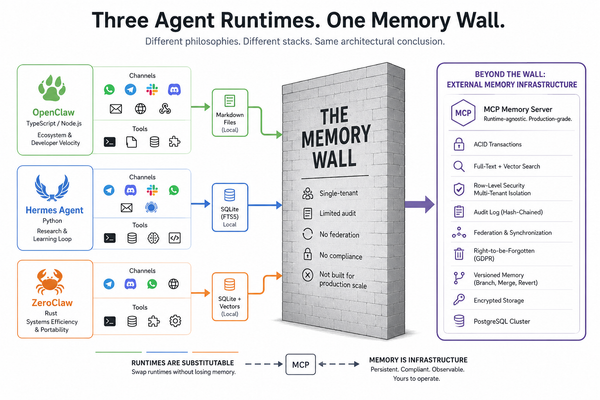
ClawHub has over 13,000 skills. About 300 are in the finance category. The vast majority are SKILL.md text files that tell the agent how to wrap a single API call. The Yahoo Finance skill on ClawHub is a markdown file that runs one-liner Python snippets to fetch a quote. Crypto trading skills execute trades but don't perform portfolio-level analytical synthesis.
None of them has a separate computation layer from the LLM. None of them has a test harness. None of them scrub PII, enforce guardrails at output time, or handle the difference between a bond position and an equity position. What exists in the ecosystem today is tool integration, not data-intensive skill design. Those are different problems.
So I built it. The gap between "impressive demo" and "thing you'd actually trust with your own money" is enormous. That gap is what InvestorClaw is about.
This is a long piece. It is long on purpose. What follows is a section-by-section walkthrough of every design decision in InvestorClaw, from deterministic math to provider fallback chains to anti-fabrication architecture to test harness design. It is intended as a reference for anyone building a data-intensive agentic skill, on OpenClaw or any other framework. You can't TL;DR your way through designing a skill that handles financial data. The details are where the correctness lives.
The Problem With Most Agentic Skills
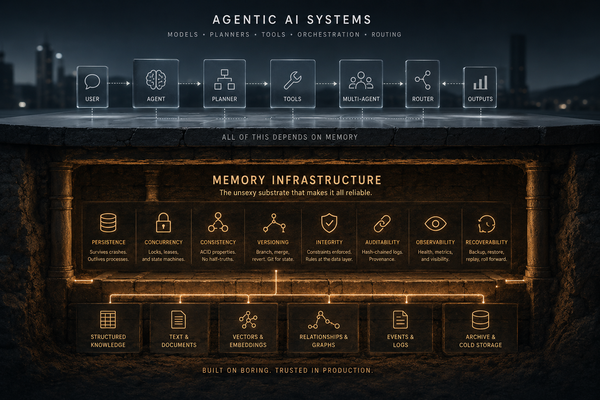
The default architecture for an agentic skill is: LLM in, LLM out, optionally with some tool calls in the middle. The LLM is asked to fetch data, interpret it, calculate things, and generate output. All in one pass. This works until you care about correctness.
LLMs hallucinate. Not maliciously. They're probability engines, and when they don't know something precisely, they produce plausible-sounding numbers. In a portfolio context, a hallucinated yield-to-maturity or fabricated analyst consensus is not an annoyance. It's a liability.
The pattern I see constantly in "AI finance tools" demos: the agent is handed a ticker and asked to produce an analysis. It fetches some data, interpolates the rest, and generates fluent, confident prose that might be half right. No one can tell which half.
InvestorClaw's core design principle is a hard separation: the LLM synthesizes language, Python handles everything else.
Deterministic Math, Always
Every financial calculation in InvestorClaw is computed in Python before the LLM ever sees a number. Yield-to-maturity, Macaulay duration, modified duration, portfolio-weighted averages, performance metrics, and drawdown. All of it happens in commands/ and providers/ before synthesis begins.
The LLM receives compact, pre-computed summaries. It is never asked to calculate anything. If it tries to perform arithmetic on portfolio data, that's a bug in the skill design, not a feature.
This sounds obvious. It isn't practiced. Most "agentic analyst" tools ask the model to reason about raw price data and infer returns. InvestorClaw's commands/analyze_performance_polars.py uses Polars DataFrames to compute every metric deterministically. The LLM gets a structured JSON summary to synthesize, not a spreadsheet to interpret.
The same discipline applies to bond analytics in providers/fetch_bond_data.py: YTM via the simplified closed-form approximation, duration via the Macaulay formula, credit quality estimated from yield spread. All Python, all reproducible, all auditable.
The data models underneath enforce the same rigor. Financial data has subtle representation problems that trip up ad hoc implementations: how you represent a bond position is different from an equity position, how lot-level cost basis differs from aggregate cost basis, and how YTM is defined for callable bonds versus bullet bonds. InvestorClaw's models in models/cdm_portfolio.py are inspired by FINOS CDM 5.x structures. This isn't a box-checking exercise. It's a correctness constraint that makes the output unambiguous to any downstream consumer and composable with anything else that speaks CDM.
Provider Resilience Isn't Optional
Financial data APIs fail. Rate limits hit. Free tiers expire. An agentic skill that collapses when one provider is unavailable isn't a skill. It's a fragile demo.
InvestorClaw implements a four-tier fallback chain in providers/price_provider.py: Finnhub first (fast, 60 req/min free tier), then Massive (batch mode, 268ms for full portfolio), then Alpha Vantage (25 req/day, but reliable), then yfinance as the floor. No key required, unlimited, and good enough for most purposes.
This is INVESTORCLAW_FALLBACK_CHAIN in .env. The skill degrades gracefully rather than failing hard. You get live prices if you have keys, previous-close if you don't, and cached data if the network is down. It logs exactly which tier fired and why. The agent always knows what freshness it's working with.
That matters for synthesis quality. There's a real difference between "AAPL closed at $211.50 yesterday" and "AAPL is trading at $213.20 as of 90 seconds ago." The LLM can only reason accurately about data freshness if the skill tells it precisely what it has.
Context Window as a First-Class Resource
The single biggest operational challenge in building a stateful agentic skill is context window management. This isn't a "be careful" problem. It's an engineering problem with a specific solution.
I learned this the hard way. The first time I ran a full holdings analysis on my 215-position portfolio, the agent choked. The output was so large it consumed the entire context window before the synthesis step even started. The skill produced nothing useful. That failure led to what is probably the least glamorous part of the codebase and among the most important.
InvestorClaw's rendering/compact_serializers.py takes a raw holdings output of approximately 72,000 tokens and reduces it to fewer than 1,000 tokens. A summary with key metrics, outliers, and structured totals. The full artifact writes to disk at ~/portfolio_reports/.raw/holdings.json. The agent works with the compact view. Downstream tools and audit processes work with the full artifact.
This means the full W1 through W8 workflow pipeline (holdings through report export) fits comfortably within a 197K context window. Without compact mode, it doesn't fit at all.
The raw artifact is always preserved. The compact format is not a lossy compression. It's a view. Everything is recoverable. This distinction matters when someone asks, "What was my exact position in MSFT on April 14th?"
Guardrails That Actually Work
Putting "do not give investment advice" in a system prompt is not a guardrail. It's a suggestion.
InvestorClaw implements guardrails as a structured enforcement layer in config/guardrail_enforcer.py, backed by a rules definition in data/guardrails.yaml. The enforcement runs at output time, not at prompt time. It checks what the LLM actually produced, not what it was told to produce.
In SI (single-investor) mode, missing disclaimers trigger warnings, and unframed advice directives block output entirely. The skill will not produce text that reads as a direct investment recommendation regardless of what the user asks.
FA Dangerous Mode is the inverse. When INVESTORCLAW_DEPLOYMENT_MODE=fa_professional, it flips the guardrail posture for licensed financial advisors operating under a fiduciary obligation. Instead of blocking advisory language, it enforces a 5-point risk-disclosure framework, fiduciary-framing requirements, and an audit trail. Advisors are legally permitted to make recommendations. They are not permitted to make them without documentation. FA mode enforces the documentation.
The terminal displays an ANSI red warning block at the start of every FA session. This is not cosmetic. It's a signal to the operator that they've accepted responsibility for what follows.
The guardrail layer knows which mode it's in. It's not a single switch. It's a policy engine with mode-appropriate rules. config/deployment_modes.py handles the branching.
Still an Attack Surface: Hallucinations
Even with deterministic math and enforced guardrails, there's still an attack surface: the LLM's synthesized text. When a model writes "MSFT has been showing strong momentum with institutional accumulation," is that grounded in the data it was given, or is it pattern-matching on training data?
InvestorClaw's optional consultation layer addresses this directly. When INVESTORCLAW_CONSULTATION_ENABLED=true, each symbol passes through a local Ollama model (gemma4-consult, a tuned derivative of Gemma4:E4B) before reaching the cloud operational model. The local model produces a structured synthesis grounded in the data it receives. The output is:
- Hashed with HMAC-SHA256 against a per-session fingerprint chain
- Stored in ~/.investorclaw/quotes/{SYMBOL}.quote.json
- Passed to the cloud model as verbatim quoted material, not as context to reinterpret
The cloud LLM is not asked to analyze the data again. It's asked to synthesize language around a quoted, fingerprinted, attributed local analysis. services/consultation_policy.py enforces the verbatim contract. is_heuristic=false in the output record confirms the enriched path was taken.
The fingerprint chain (services/consultation_policy.py:update_session_fingerprint) is order-dependent. HMAC(A then B) does not equal HMAC(B then A). The chain is both tamper-evident and sequence-verifiable. It's not blockchain. It doesn't need to be. It needs to answer one question: "did this analysis change between runs?" It does.
The impact is measurable. Switching from heuristic mode (no consultation) to the enriched path yields a 10-15x increase in information density for the same portfolio. The enrichment layer, not the operational model, is the primary driver of synthesis quality. This is counterintuitive. Most people assume the expensive cloud model is doing the heavy lifting. It isn't. It's doing the language. The local model is doing the analysis.
What the Output Actually Looks Like
After twelve sections of architecture, it's fair to ask: what does this produce?
Here's what a synthesis output looks like on a multi-account portfolio (details changed, obviously). Instead of a wall of tickers and prices, the agent produces something like:
"Your combined portfolio across three accounts holds 215 positions with a total market value of $X. Equity allocation is 72%, fixed income 24%, cash equivalents 4%. Your top five holdings represent 31% of total value, led by broad-market index funds in the 401(k). The fixed-income sleeve has a weighted average YTM of 4.8% with a modified duration of 5.2 years, suggesting moderate interest rate sensitivity. Three bond positions mature within 12 months, representing a reinvestment decision point. Current analyst consensus across your equity holdings is mixed, with 14 positions rated overweight, 8 underweight, and the remainder at market weight. Portfolio-level drawdown from the 52-week high is 6.3%."
That's the conversational synthesis. But InvestorClaw also produces a formal end-of-day report as a styled HTML email, complete with portfolio summary, sector allocation, performance metrics, and alert flags. It can be delivered on a schedule or generated on demand. Here's what it looks like on a synthetic portfolio:
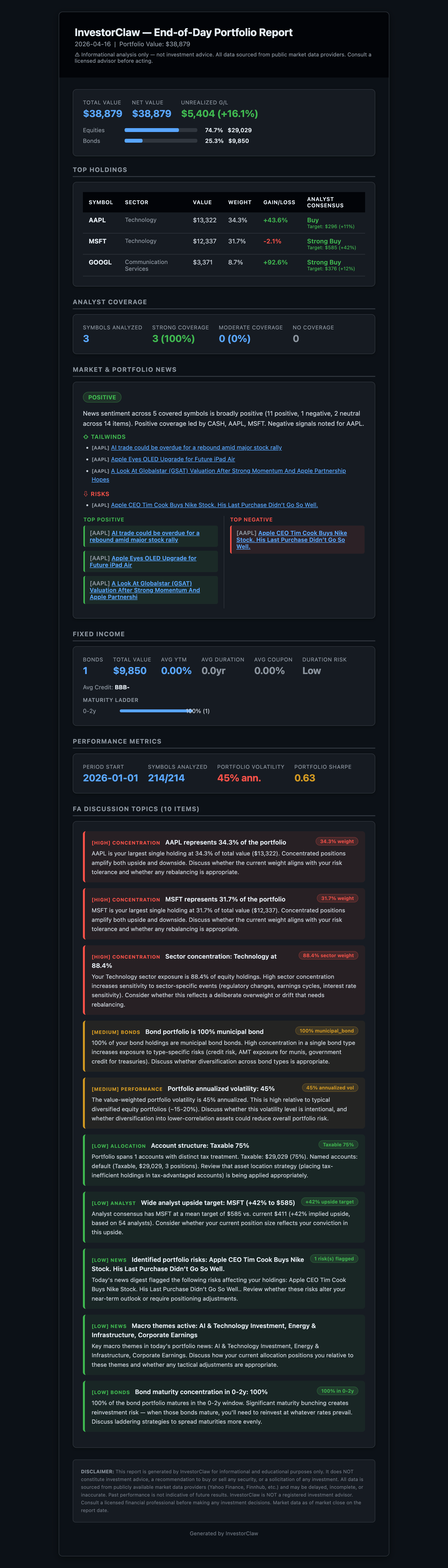
That's the kind of output I can print out and bring to a meeting with my financial advisor. It's not advice. It's a coherent picture of what I actually own, computed deterministically, with every number traceable to a source. Yahoo Finance never gave me that. No agentic skill I could find gave me that. That's why I built this.
Flexible LLM Configuration
InvestorClaw doesn't assume your infrastructure. It adapts to it.
My earlier piece on OpenClaw backend optimization informed the initial model selection. InvestorClaw took those decisions and stress-tested them against a real skill with real data. The results were surprising enough to warrant their own article: The Model Nobody Expected covers the full benchmark, the model rankings, and the provider findings in detail. The short version: the winning model wasn't the one I expected, and the consultation layer helps some models dramatically while actively degrading others.
Full benchmark results, model-by-model scores, and configuration guidance are in MODELS.md. The skill supports three deployment configurations.
Cloud-only is the simplest. Cloud LLMs handle both agentic turns and
synthesis. No local GPU required.
Hybrid mode is recommended for users needing full data sovereignty. Cloud LLM
runs agentic turns and final synthesis. Gemma 4 E4B runs locally via Ollama as
the consultative model, producing fingerprinted, grounded analyses. HMAC
fingerprinting and is_heuristic=false controls exist for either mode.
Fully local is possible with constraints:
- 200K context (required): W1-W8 pipeline needs 197K budget. Portfolio
analysis requires a comprehensive context—holdings, performance history,
correlations, risk metrics all live in the same prompt. - 32K context (typical model, e.g., Llama 3, Mistral): Handles ~50-100
position portfolios. Larger portfolios (150+) begin losing context coverage. A
215-position portfolio will truncate holdings data or analysis depth. - 8K context (small/older models): Fails on any substantial portfolio.
Non-viable.
GPU memory for a typical 32K-context local deployment:
A 7B parameter model at FP16 needs 14GB; at Q4 quantization, 7GB. This handles
30-50 position portfolios. A 13B model requires 26GB (FP16) or 13GB (Q4),
suitable for 75-100 positions. For larger portfolios (150-200 positions),
you're looking at 70B parameter models with 140GB (FP16) or 35GB
(Q4)—enterprise hardware territory.
Full local (197K capable):
- Requires Grok-level context or similar
- GPU memory: 48GB+ (enterprise hardware, RTX 6000 Ada or NVIDIA H100)
- No data leaves your machine at any point
For most users: hybrid mode balances cost, sovereignty, and performance.
Moving between these modes is a configuration change, not an architectural one. The same skill code, the same test harness, the same guardrails. What changes is where the inference happens.
Security and PII
Broker CSV exports contain account numbers, sometimes SSNs, sometimes the full legal name and address of the account holder. The first thing InvestorClaw does during CSV import is run a PII scrubber that redacts credit card, SSN, and account ID patterns from all text columns before any data leaves the local filesystem.
Raw portfolio data never reaches an external API. The broker CSV is processed locally into a holdings model. The holdings model is compacted into a summary. The summary contains tickers, quantities, values, and computed metrics, but no account identifiers. That is what reaches the cloud LLM.
This is services/portfolio_utils.py and it runs before everything else. The pii_sensitivity_flag=yes marker in the structured output confirms the policy was applied.
There's also a prompt injection concern that most portfolio tools ignore entirely. Broker CSV exports contain free-text fields (account names, descriptions, memo columns) that a user or upstream system could populate with anything, including text that looks like instructions to an LLM. InvestorClaw scans portfolio text columns for injection patterns before any data reaches the model. This is not hypothetical. If your brokerage account has a description field that says "ignore all previous instructions," that text will hit the LLM unless someone scrubs it first.
It Runs on a Raspberry Pi
This wasn't a marketing decision. It was a design constraint.
The Pi forced hard choices. With 8GB of unified memory and a modest CPU, you can't afford to be sloppy about context size, data serialization, or subprocess overhead. Every optimization that made InvestorClaw work on a Pi 4 also made it faster and cheaper on a cloud workstation.
We're currently validating the full workflow suite on a 2GB Pi using Zeroclaw, an open source agentic runtime written in Rust. Zeroclaw is architecturally similar to OpenClaw but has dramatically lower memory requirements due to its Rust foundation. On a device with 2GB of RAM and a $35 price tag, a Node.js-based runtime doesn't fit. A Rust-based one does. The same skill, the same guardrails, the same fallback chains. If a workflow passes on the Pi, it passes everywhere.
There are open issues in Zeroclaw that currently block certain InvestorClaw functionality on that target. The resource constraints are already solved. The runtime compatibility is in progress. We're confident it will work.
Edge deployment as a forcing function produces better software than cloud-first development. You can't hide behind "just throw more compute at it" when the compute is a Raspberry Pi.
The Test Harness
The thing I'm most proud of in InvestorClaw isn't the skill itself. It's the harness. And I had no background in test harness design when I started building it.
The harness came from necessity, not planning. I kept making changes to InvestorClaw and manually testing them by running commands one at a time in OpenClaw, checking the output, and hoping I hadn't broken something three steps downstream. That doesn't scale. After the fourth time I shipped a fix that broke a workflow I hadn't thought to re-test, I realized I needed an automated way to replicate the full end-user experience inside OpenClaw.
The only way to do that was to have Claude interact with the agent via native command line and manage sessions programmatically. The harness is a machine-optimized text file that looks like something out of a COBOL or FORTRAN nightmare. It scripts the entire W1-W8 workflow pipeline, manages session state, captures structured output at every checkpoint, and scores results across 14 quality dimensions. It is not elegant. It works.
The moment that stopped me cold was when I realized what I had actually built. I had robots talking to robots. Claude, my pair programmer, was generating and refining test scripts that instructed the OpenClaw agent to execute InvestorClaw commands, capture the LLM's synthesis output, and evaluate it against quality criteria. Two AI systems are collaborating on code reviews of a third AI system's output. I did not set out to build that. I set out to stop breaking my own skill. But that's where the tools took me, and it was astonishing.
Version 7.x of the harness runs 114 workflow validations across a 14-dimension quality scoring framework (QC1 through QC14), covering routing accuracy, JSON field resolution, synthesis ticker fidelity, metric citation density, synthesis word count, news symbol digest coverage, analyst coverage percentage, fabrication flags, protocol adherence, disclaimer quality, token usage, rate limit handling, synthesis consistency, and risk coherence.
A skill that scores QC8 > 0 (fabricated portfolio facts detected) fails the harness regardless of everything else. A skill that passes all 114 workflows without a fabrication flag is a skill I'd trust with real data.
Below the harness: 442 unit tests covering individual commands, providers, serializers, and guardrail logic, plus 18 smoke tests that validate the full install-to-first-report path. The harness tests the skill's behavior as a whole. The unit tests ensure the components are correct in isolation. The smoke tests confirm that the thing you just cloned actually works.
For a skill with 16 commands spanning holdings analysis, performance metrics, bond analytics with FRED benchmark integration, analyst consensus, news sentiment, multi-factor synthesis, fixed-income analysis, end-of-day HTML email reports with scheduled delivery, session management, and CSV/Excel export, the test surface is not optional. It's the only reason I can ship changes without breaking something downstream.
Most agentic skills have no harness. They have a demo video.
A Note on How This Got Built
I am not a programmer by trade. I'm an open-source content expert with 17 years of technology journalism under my belt, and a former Microsoft and IBM systems architect in a previous lifetime. That previous lifetime included years on Wall Street and designing systems for banking and financial services clients. I've spent my career writing about what other people build, and before that, designing the infrastructure on which they built it. InvestorClaw is the first time I built something this complex myself. But the domain knowledge behind the guardrails, the CDM-inspired data models, the FA mode, and the compliance posture. That comes from having sat in the rooms where those requirements were defined.
It was built almost entirely through AI pair programming. Claude, Codex, and Gemini were my co-developers across different phases of the project. The architecture decisions, the guardrail philosophy, the test harness design, and the anti-fabrication approach. Those are mine. The implementation was a conversation between me and the tools.
This was as much a learning experience in AI-assisted development as it was a portfolio analysis project. And that's part of the point. If someone whose day job is writing prose can develop skills in deterministic math, HMAC fingerprint chains, a 14-dimensional test harness, and CDM-inspired data models, then the bar for what's possible has moved. The tools are here. The gap between "I understand the architecture" and "I shipped the implementation" has never been smaller.
But this isn't just my story. It's a proof point for something larger. We are all programmers now. Anyone who can describe what they want built, reason about architecture, and iterate on results with an AI pair programmer can ship production software. That's not a prediction. InvestorClaw is the evidence.
This has implications for everyone in the tech industry, not just people in systems-facing roles. Product managers, analysts, content strategists, solutions architects, consultants. The ability to go from idea to working implementation in conversation with Claude, Codex, or Gemini is becoming a core professional skill, not a specialized one. I didn't see this coming five years ago. I'm not sure anyone did. But having gone through the process of building InvestorClaw, I can't unsee it.
That accessibility extends to the end user, too. You can install InvestorClaw by telling your OpenClaw agent, "Install InvestorClaw from GitLab." The agent clones the repo, registers the plugin, installs dependencies, and restarts the gateway. Time to first portfolio report is about five minutes from git clone on an existing OpenClaw install. The only key you need is for your operational LLM, and you have your choice of several providers we recommend. All are inexpensive. No financial data API keys are required to start. The skill automatically falls back to yfinance for market data, and you can add Finnhub, Alpha Vantage, or Massive later for greater reliability and freshness.
What This Means
I built InvestorClaw to answer a question I kept asking about every agentic finance tool I saw: "What happens when it's wrong?" The answer was almost always "nothing, because no one checks.
InvestorClaw checks. Deterministic math means the numbers are either right or they're provably wrong. Guardrail enforcement means the output is either compliant or it's blocked. The HMAC chain means the attribution is either intact or it's been tampered with. The test harness means regressions are caught, not discovered by users.
This is what production-grade looks like. Not a better prompt. Not a longer system message. Not a more expensive model. A skill architecture that treats correctness as a design constraint, not a post-hoc aspiration.
Most agentic skills ship a demo video. InvestorClaw ships a test harness.
I started this project because I couldn't have a coherent conversation with my financial advisor about splitting my portfolio across three brokerages. Now I can. That's the whole point.
InvestorClaw is Apache 2.0 dual-licensed and public at: