Mnemos: A Memory Operating System for Agentic AI


Why I built my own memory substrate for long-running AI agents — and what "co-author" actually means in practice
Published: April 22, 2026 Read time: 6 minutes Topics: Open Source, Agentic AI, Systems Architecture
Disclosure: This post reflects independent personal experimentation and my own hands-on work on personal open-source projects. It reflects only my personal views, is not professional advice, and does not represent any organization, employer, or official position.
This week Mnemos v3.1.0 shipped under Apache 2.0. FastAPI plus PostgreSQL, Python 3.11+. It has been in daily production use since December 2025, backing two personal projects (RiskyEats and InvestorClaw) simultaneously.
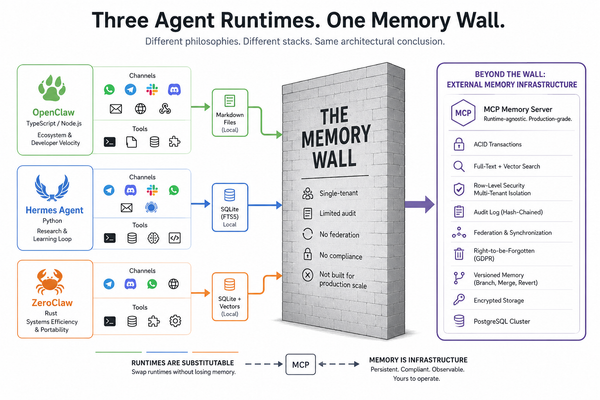
Mnemos is a memory operating system for agentic AI. Not a memory storage provider. An OS.
That distinction is the whole point. This post is the short version of why it matters. The project README is where the actual details live.
Where This Came From
If you read Adventures in Extreme Vibecoding back in December, this is what the development cycle described there eventually needed as infrastructure.
You can vibecode a restaurant-inspection ETL for a few weeks on conversation history alone. You cannot build anything durable that way. Sessions end. Context evaporates. Decisions from three weeks ago have to be reconstructed from chat logs and scattered markdown files. The off-the-shelf options — in-process memory libraries, conversation-summary buffers, raw vector stores — solve part of the problem badly.
By January, it was obvious that the memory substrate had to stop being an afterthought and become its own system. Mnemos is that system.
It ran in production on a single machine for four months before I cut it open for v3.1.0 this week. It currently holds 6,793 memories across two projects, with 3,077 compressions — each one carrying a written receipt of what was removed, what was preserved, and what the compressed version is and isn't safe for. That's unusual enough that it's worth saying why.
An OS, Not a Storage Provider
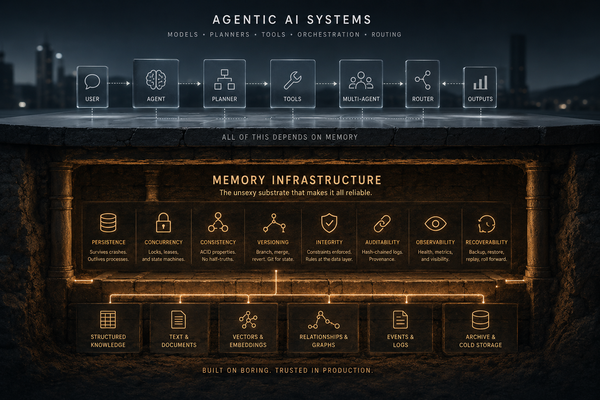
A storage provider gives you a place to put bytes. An operating system provides named subsystems — a scheduler, a compressor, a process manager, a security layer, and an auditor — that cooperate to manage the full lifecycle of a resource, so the application no longer has to babysit it.
Most tools in this space are the first thing dressed up to look like the second. Mnemos is the second thing.
What that looks like in practice: every memory carries provenance. Every compression leaves a receipt. Every reasoning step across multiple LLM providers hits a cryptographic audit chain. Every foreign-key edge in the schema carries an explicit opinion about what happens when the thing it points at goes away. Federation, OAuth, webhooks, and DAG-versioned memory are services built on top of a kernel, not features bolted onto a library.
The thing you're supposed to feel reading that paragraph is: yeah, that's what production infrastructure is supposed to look like, and I'm tired of memory systems that don't.
Mnemos is for the second group.
Who This Is For (And Who It Isn't)
If you are building a single-user chatbot for personal note-taking, Mnemos is more architecture than you need. Most of what it offers — the audit chain, the multi-agent isolation, the compression receipts, the consensus reasoning — would sit dormant for that use case. Mem0, Zep, and in-process summary buffers are shaped for single-user single-agent work and do it well. Use those.
If you are running multiple agents or multiple LLM providers and they need to share a memory pool that survives process restarts and provider outages, if you produce outputs someone downstream has to trust, if you care whether your memory layer can silently corrupt or truncate things — Mnemos is designed for you.
Specifically, it's the answer for the 56-year-old former IBM / Microsoft veteran who has been thoroughly indoctrinated into architectural thinking and mission-critical design, and physically cringes at a memory layer that doesn't have the -isms and -itabilities thought through: atomicity, idempotency, referential integrity, ACIDism on the write path; durability, recoverability, observability, auditability, testability on the operate path. The things your old DBA would have red-pen'd in a review twenty years ago and your old SRE would red-pen now.
This is for you. We know.
Two Things Worth Clicking Through For
The README has the full technical surface. Two things are worth calling out here because they're what make Mnemos different, not just larger:
Compression with a receipt. Every time Mnemos compresses a memory — on write, before a consultation, on rehydration — it writes a manifest: what was removed, what was preserved, the quality rating, and which use cases the compressed version is and is not safe for. No other memory system treats compression as something that needs a receipt. If you've ever had an LLM summarize a long context for you and then acted on the summary, only to discover that something critical had quietly been dropped, you understand why this matters. Mnemos names the tradeoff instead of hiding it.
A reasoning layer that keeps itself current. Most multi-LLM routers hardcode a provider list and drift out of date within weeks. Mnemos ships a self-populating PostgreSQL-backed model registry that syncs daily from provider APIs and quarterly from the Arena.ai leaderboard. A provider that drops on Arena.ai also drops in Mnemos's internal routing on the next timer tick, without a human touching a config file. That's the difference between a router that's current on the day you deploy and a router that stays current.
Both of those are fully described in the README. I'm not going to re-explain them here. They're the two reasons the README is worth your time if the rest of this post resonates.
What "Co-Author" Means
Two years ago, I could not have written any of this. Not the pgvector schema, not the FastAPI wiring, not the hash-chained audit writer with its advisory-lock-serialized tip read, not the OAuth callback flow, not the federation dedup logic.
The systems-thinking decisions are mine. Which relationships cascade. Which set null. Which operation needs a lock and at what granularity. What the compression manifest has to carry for the output to be defensible in a compliance review. Those come from 30 years of watching systems fail in production.
The code that expresses those decisions came from working with Claude.
I held the architectural opinions. Claude held the syntax and the language-specific idioms. The result runs in production. It isn't a demo.
Further Reading
- Mnemos source, README, and full technical detail: github.com/perlowja/mnemos (Apache 2.0, v3.1.0)
- Companion post on the upstream PRs that came out of testing Mnemos integrations: From 30 Years in IT to Shipping Real Fixes: How AI Changed the Contribution Gameprovides named subsystems — a scheduler, a compressor, a process manager, a security layer, and an auditor — that cooperate to manage the full lifecycle of a resource, so the application no longer has to babysit it
- The December 2025 prequel on where all of this started: Adventures in Extreme Vibecoding
- InvestorClaw, one of the two projects Mnemos was built to support: github.com/perlowja/InvestorClaw